



There, that's known as a teaser. You see it in television all the time. "Find out which common household plant devours pets at night...but first." And then you have to sit through and watch the stuff about Brad and Angelina shacking up / Shaq driving his new Hummer / Hummer's new fragrance before they get to the good stuff, the petnivorous plants. I don't know what I'd do without TiVo. And here I've done the same thing as the networks. Shame on me. I'll get to it, I promise.
But first
But first, let's talk about data structures. I'll try to make this more interesting than Donald Trump's new reality fragrance SUV. Data structures are really important, we're lead to believe, so important that entire classes in CS curricula discuss nothing else all year. Gosh! Let's look at all the data structures we have available in Java.
| HashSet | TreeSet | LinkedHashSet | ArrayList |
| LinkedList | PriorityQueue | HashMap | TreeMap |
| LinkedHashMap | WeakHashMap | IdentityHashMap | CopyOnWriteArrayList |
| CopyOnWriteArraySet | EnumSet | EnumMap | ConcurrentLinkedQueue |
| LinkedBlockingQueue | ArrayBlockingQueue | PriorityBlockingQueue | DelayQueue |
| SynchronousQueue | ConcurrentHashMap |
Here's the data structures we have in standard C++:
| vector | deque | list | slist |
| bit_vector | set | map | multiset |
| multimap | hash_set | hash_map | hash_multiset |
| hash_multimap | stack | queue | priority_queue |
| bitset |
CoreFoundation
I'm going to compare those to CoreFoundation. CoreFoundation, if you're a bit hazy, is Apple's framework that "sits below" Carbon and Cocoa, and is one of the few places where these two APIs meet. CoreFoundation has collections, so that other APIs like Quartz that take and return collections don't need separate Carbon and Cocoa interfaces. But the real reason I'm talking about CoreFoundation is that it's open source.
Here's all the CoreFoundation collections, leaving out the immutable variants:
| CFMutableDictionary | CFMutableBag | CFMutableBitVector | CFMutableSet |
| CFMutableArray | CFBinaryHeap | CFMutableTree |
Right?
The array that wasn't
Take a look in CFArray, at this strange comment:The access time for a value in the array is guaranteed to be at worst O(lg N) for any implementation, current and future, but will often be O(1) (constant time). Linear search operations similarly have a worst case complexity of O(N*lg N), though typically the bounds will be tighter, and so on. Insertion or deletion operations will typically be linear in the number of values in the array, but may be O(N*lg N) clearly in the worst case in some implementations. There are no favored positions within the array for performance; that is, it is not necessarily faster to access values with low indices, or to insert or delete values with high indices, or whatever.
It's like Apple skipped out on some sophomore CS lectures. Everyone knows that arrays don't have logarithmic lookups - they have constant time lookups. But not these "arrays!" (necessarily!) In fact, you might notice that the guarantees Apple does make are weak enough for CFArray to be a hash table or binary tree. Talk about implementation latitude! Is there any payoff?
Let's try some operations and see how CFArray compares. Well take an array with 100,000 values in it and time inserting, deleting, and getting items, each from the beginning, end, and random positions, for CFArrays, an STL vector, and a "naïve" C array. Then we're going to do it again starting with 200,000 elements, then 300,000, etc. up to one million. Whoo, that's a lot of permutations. I don't want to do all that. Lovely assistant?
Lov. Asst.: Mmmmm, sir?
Go write that thing I said.
Lov. Asst.: Yes, sir.
Isn't she great?
Lov. Asst.: Done, sir.
Thank you. I've enclosed my source code here; if you want to reproduce my results, run the test.py file inside it. As I said, we're doing various operations while varying the initial size of the array. All of the results are expressed as a multiple of the result for an array with 100,000 values. That means that if the green line is higher than the red one, it doesn't mean that the green operation was more expensive than the red one in absolute terms, but that the green one slows down more (as a percentage) than the red one as the array size increases. A line going up means that the operation becomes more expensive with larger arrays, and a line staying flat means its expense does not change.
Graphs
Here's what I get for my quicky naïve C array: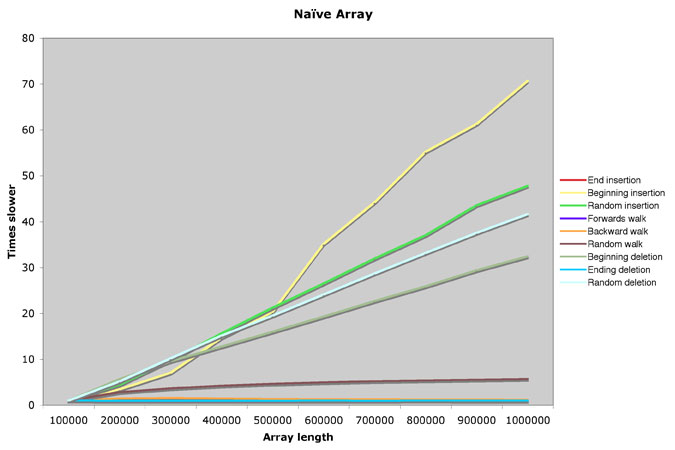
Ok, so what does this mean again? The green line is at about 50 for a length of 1,000,000, so inserting data at random locations in my C array is about 50 times slower than doing it for a length of 100,000. (Ouch!) But no real surprises here; insertion at the end is constant (flat), insertion at random locations or at the beginning is roughly linear.
Here's what I get for the STL vector template:
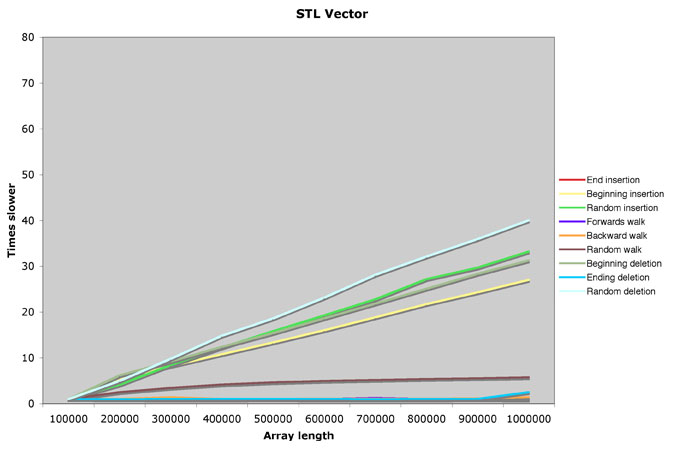
Right out of a textbook. Insertions and deletions take linear time, except for at the end where they take constant time, and lookups are always constant.
Now for CFArray:
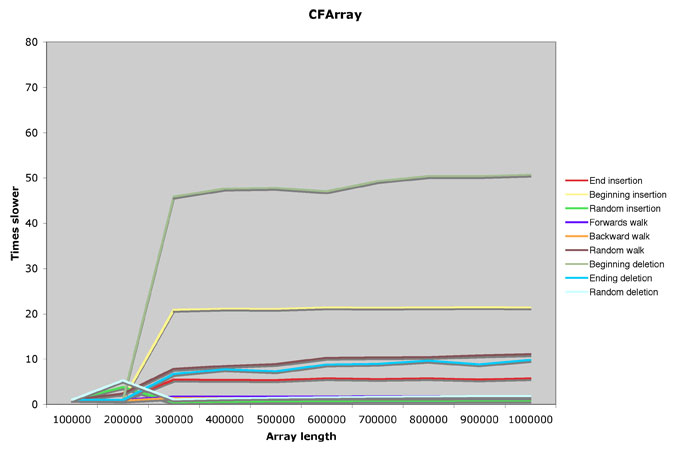
Say what? I was so surprised by this, I had to rerun my test, but it seems to be right. Let's catalog this unusual behavior:
- Insertion or deletion at the beginning or end all take linear time up to 300,000 elements, at which point they start taking constant time; the operations for large arrays are no more expensive than for arrays of 300,000 elements.
- Insertion or deletion at random locations starts out taking linear time, but suddenly becomes less expensive and switches to constant time. Insertion in an array of 1,000,000 elements is as expensive as for 100,000 elements, but 200,000 is more expensive than either.
- Walking forwards or backwards takes constant time (as expected), but walking in a random order appears to take linear time up to about 300,000 elements - something very unusual (usually it's equally as fast to access any element). This suggests that there is some remembered state or cache when accessing elements in a CFArray. (And CFStorage, used by CFArray, seems to confirm that.)
So it sure looks like CFArray is switching data structure implementations around 30,000 elements. And I believe there's lots more implementations that I haven't discovered, for smaller arrays and for immutable arrays.
So what?
I guess I've got to come to a conclusion or three. Ok, here we go, in order of increasing broadness:
- CFArrays and NSArrays are good at some things that arrays are traditionally bad at. Don't go rolling your own dequeue just because you plan to insert a lot of stuff in the beginning of an array. Try CFArray or NSArray first, if they're easier, and optimize if it's too slow or doesn't fit.
- Apple often (though not always) names a class in terms of what it does, not how it does it. This is the spirit of Objective-C dynamic messaging: a message says what to do, but not how to do it. The way it does it may be different from what you expect. Which leads me to:
- Don't second guess Apple, because Apple has already second guessed YOU. In a good way, of course.