



Why now?
My friend over at SciFiHiFi suggests that Microsoft likes trees, but Apple likes hash tables. Well, I think that Microsoft prefers integer arithmetic, while Apple (or at least Cocoa) likes floating point. Here's a bunch of examples I found:- Take color. Microsoft's API (you know, THAT one) makes colors from integer components, but Cocoa makes colors from floats.
- Microsoft does sliders (like the iTunes volume control) with with integers, but NSSlider is floating point.
- Time, too. Microsoft does time in integers, but Apple does it with doubles.
(Apple does it with doubles - hey, that's a good bumper sticker.)
Ahem. Ok, so Apple is floating-point happy. (And it didn't always used to be this, way, of course. Quickdraw used integer coordinates, and Quartz switched to floating point, remember?). So, as a Mac programmer, I should really get a good handle on these floating point thingies. But floating point numbers seem pretty mysterious. I know that they can't represent every integer, but I don't really know which integers they actually can represent. And I know that they can't represent every fraction, and that as the numbers get bigger, the fractions they can represent get less and less dense, and the space between each number becomes larger and larger. But how fast? What does it all LOOK like?
Background
Well, here's what I do know. Floating point numbers are a way of representing fractions. The Institute of Electrical and Electronics Engineers made it up and gave it the memorable name "IEEE 754," thus ensuring it would be teased as a child. Remember scientific notation? To represent, say, 0.0000000000004381, we can write instead 4.381 x 10-13. That takes a lot less space, which means we don't need as many bits. The 4.381 is called the mantissa, and that -13 is the exponent, and 10 is the base.Floating point numbers are just like that, except the parts are all represented in binary and the base is 2. So the number .01171875, that's 3 / 256, would be written 11 x 2-100000000.
Or would it? After all, 3/256 is 6/512, right? So maybe it should be 110 x 2-1000000000?
Or why not 1.1 x 2-10000000?
Ding! That happens to be the right one; that is, the one that computers use, the one that's part of the IEEE 754 standard. To represent a number with floating point, we multiply or divide by 2 until the number is at least 1 but less than 2, and then that number becomes the mantissa, and the exponent is the number of times we had to multiply (in which case it's negative) or divide (positive) to get there.
Tricksy hobbit
Since our mantissa is always at least 1 but less than 2, the 1 bit will always be set. So since we know what it will always be, let's not bother storing it at all. We'll just store everything after the decimal place. That's like saying "We're never going to write 0.5 x 10-3, we'll always write 5. x 10-4 instead. So we know that the the leftmost digit will never be 0. That saves us one whole numeral, the numeral 0." A WHOLE numeral. Woo-hoo? But with binary, taking out one numeral means there's only one numeral left. We always know that the most significant digit is 1, so we don't bother storing it. What a hack! Bit space in a floating point representation is almost as expensive as housing in Silicon Valley.
So the number 3 / 256 would be written in binary as .1 x 2-10000000, and we just remember that there's another 1 in front of the decimal point.
Unfair and biased
We need to store both positive exponents, for representing big numbers, and negative exponents, for representing little ones. So do we use two's complement to store the exponent, that thing we hated figuring out in school but finally have a grasp on it? The standard for representing integers? (The exponent is, after all, an integer.) Nooooooo. That would be toooooo easy. Instead, we bias the number. That just means that the number is always stored as unsigned, ordinary positive binary representation, but the REAL number is what we stored, minus 127! So if the bits say the exponent is 15, that means the REAL exponent is -112.
A good sign
We also need to represent positive and negative numbers (remember, a negative exponent means a small but positive number; we don't have a way of representing actual negative numbers yet). At least there's no real trickery involved here - we just tack on a bit that's 0 for a positive number, and 1 for a negative number.
Let's make a float
So now that we have a handle on all the bizarre hacks that go into representing a float, let's make sure we did it right. Let's put together some bits and call them a float. Let me bang some keys on the top of my keyboard: -358974.27. There. That will be our number.
First, we need a place to put our bits that's the same size as a float. Unsigned types have simple bit manipulation semantics, so we'll use one of those, and start with 0.
unsigned val = 0;
Ok, next, our number is negative, so let's set the negative bit. In IEEE 754, this is the most significant bit.
unsigned val = 0;
val |= (1 << 31);
All right. Start dividing by 2. I divided 18 times and wound up with 1.369 something, which is between 1 and 2. That means that the exponent is 18. But remember, we have to store it biased, which means that we add 127. In IEEE 754, we get 8 bits for the exponent, and they go in the next 8 most significant bits.
unsigned val = 0;
val |= 1 << 31;
val |= (18 + 127) << 23;
Now the mantissa. Ugh. Ok, 358974.27 in straight binary is 1010111101000111110.010001010001 and then a bunch of others 0s and 1s. So the mantissa is that, minus the decimal place. And IEEE 754 says we get 23 bits for it. So first, chop off the most significant bit, because we know it will always be one, and throw out the decimal point, and then round to 23 bits. That's 01011110100011111001001, which is, uhh, 3098569. There. That's our mantissa, which occupies the remaining 23 bits.
unsigned val = 0;
val |= 1 << 31;
val |= (18 + 127) << 23;
val |= 3098569;
Ok, let's pretend it's a float, print it out, and see how we did!
#include <stdio.h> int main(void) { unsigned val = 0; val |= 1 << 31; val |= (18 + 127) << 23; val |= 3098569; printf("Our number is %f, and we wanted %f\n", *(float*)&val, -358974.27f); return 0; }
This outputs:
Our number is -358974.281250, and we wanted -358974.281250Hey, it worked! Or worked close enough! I guess -358974.27 can't be represented exactly by floating point numbers.
(If you're on a little-endian machine like Intel, you have to do some byte-swapping to make that work. I think.)
Loose ends
There's a few loose ends here. Remember, we get the mantissa by multiplying or dividing until our number is between 1 and 2, but what if our number started out as zero? No amount of multiplying or dividing will ever change it.
So we cheat a little. We give up some precision and make certain exponents "special."
When the stored exponent is all bits 1 (which would ordinarily mean that the real exponent is 128, which is 255 minus the bias), then everything takes on a special meaning:
- If the mantissa is zero, then the number is infinity. If the sign bit is also set, then the number is negative infinity, which is like infinity but less optimistic.
- If the mantissa is anything else, then the number isn't. That is, it's Not a Number, and Not a Numbers aren't anything. They aren't even themselves. Don't believe me?
#include <stdio.h> int main(void) { unsigned val = -1; float f = *(float*)&val; int isEqual = (f==f); printf("%f %s %f\n", f, isEqual ? "equals" : "does not equal", f); return 0; }This outputs nan does not equal nan. Whoa, that's cosmic.
When the stored exponent is all bits 0 (which would ordinarily mean that the real exponent is -127, which is 0 minus the bias), then everything means something else:
- If all the other bits are also 0, then the floating point number is 0. So all-bits-0 corresponds to floating-point 0...phew! Some sanity!
- If all the bits are 0 EXCEPT the sign bit, then we get negative 0, which is an illiterate imperfect copy of 0 brought about by Lex Luthor's duplicator ray.
- If any of the other bits are 1, then we get what is called a denormal. Denormals allow us to represent some even smaller numbers, at the cost of precision and (often) performance. A lot of performance. We're talking over a thousand cycles to handle a denormal. It's too involved a topic to go into here, but there's a really interesting discussion of the choices Apple has made for denormal handling, and why, and how they're changing for Intel, that's right here.
Please stop boring us
So I set out to answer the question "What does it all LOOK like?" We're ready to paint a pretty good picture.Imagine the number line. Take the part of the line between 1 and 2 and chop it up into eight million evenly spaced pieces (8388608, to be exact, which is 223). Each little chop is a number that we can represent in floating point.
Now take that interval, stretch it out to twice its length, and move it to the right, so that it covers the range from 2 to 4. Each little chop gets twice as far from its neighbor as it was before.
Stretch the new interval again, to twice its length, so that it covers the range 4 to 8. Each chop is now four times as far away from its neighbor as it was before. Between, say, 5 and 6, there are only about two million numbers we can represent, compared to the eight million between 1 and 2.
Here, I'll draw you a picture.
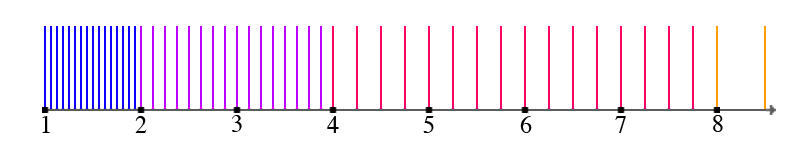
There's some interesting observations here:
- As your number gets bigger, your accuracy decreases - that is, the space between the numbers you can actually represent increases. You knew that already.
- But the accuracy doesn't decrease gradually. Instead, you lose accuracy all at once, in big steps. And every accuracy decrease happens at a power of 2, and you lose half your accuracy - meaning you can only represent half as many numbers in a fixed-length range.
- Speaking of which, every power of 2 is exactly representable, up to and including 2127 for floats and 21023 for doubles.
- Oh, and every integer from 0 up to and including 224 (floats) or 253 (doubles) can be exactly represented. This is interesting because it means a double can exactly represent anything a 32-bit int can; there is nothing lost in the conversion from int->double->int.
Zero to One
On the other side of one, things are so similar that I can use the same picture.

The squiggly line represents a change in scale, because I wanted to draw in some denormals, represented by the shorter brown lines.
- At each successive half, the density of our lines doubles.
- Below .125, I drew a gradient
because I'm lazyto show that the lines are so close together as to be indistinguishable from this distance. - 1/2, 1/4, 1/8, etc. are all exactly representable, down to 2-126 for normalized numbers, and 2-149 with denormals.
- The smallest "regular" (normal) floating point number is 2-126, which is about .0000000000000000000000000000000000000117549435. The first (largest) denormal for a float is that times .99999988079071044921875.
- Denormals, unlike normalized floats, are regularly spaced. The smallest denormal is 2-149, which is about .000000000000000000000000000000000000000000001401298.
- The C standard says that <float.h> defines the macro FLT_MIN, which is the smallest normalized floating point number. Don't be fooled! Denormals allow us to create and work with floating point numbers even smaller than FLT_MIN.
- "What's the smallest floating point number in C?" is a candidate for the most evil interview question ever.