



Blitting
Drawing an image is called "blitting." The usual way we blit is to load a pixel from the source image buffer, store it in the destination, and repeat until we've blitted every pixel.But with compiled bitmaps, the data for the image is in the instruction stream itself. So instead of "load a pixel from the source," we say "load red," and then store it as usual. Then "load green", or whatever the next color is, and store that, etc. A compiled bitmap is a function that knows how to draw a specific image.
Instruction counts
So an advantage of a compiled bitmap is that there's no need to load data from an image when we blit; the image data is in the instruction stream itself. But this is ameliorated by the fact that we'll have many more instructions in the function. How many more? That depends on the processor architecture, of course, but since I'm a Mac guy, I'll stick to PowerPC.To load a single 32 bit pixel into a register requires two instructions: one to load each 16-bit half. And storing a pixel requires another instruction. By taking advantage of the literal offset field in the stw instruction, we can avoid having to increment our destination pointer (except when we overflow the 16 bit field every sixteen thousand pixels). The PowerPC also has a special instruction form, the store word with update instructions, stwu, that lets us increment the target pointer for free. But my tests showed that to be slower than stw, which makes sense, since it introduces more inter-instruction dependencies.
But of course, if the next pixel is the same color as the current one, there's no need to load a new color into the register: you can just store the current value again. So sometimes we can get away with only one instruction per pixel. So the number of instructions per pixel in a compiled bitmap ranges between one and three, depending on the complexity of the image and the sophistication of our compiler.
This compares favorably to ordinary blitting, where we have more instructions per pixel (load pixel, store pixel, check for loop exit, and pointer updates). So at first blush, a compiled bitmap may appear ~ 33% faster than ordinary blitting.
Bandwidth
But this isn't the whole story, of course; a processor is only as fast as it can be fed. How much memory bandwidth do we use? In standard blitting, the instruction stream is a very short loop which fits entirely into the instruction cache. The main bandwidth hog is reading and writing the pixels: 32 bits read, 32 bits written. That's 32 bits each way, per pixel.With a compiled bitmap, the instruction stream no longer fits in the cache, so the instructions themselves become the bandwidth bottleneck. 32 bits for each instruction (remember, there's one to three), and 32 bits to write out each pixel, means between 32 and 96 bits read and 32 bits written per pixel. Based on that, we might expect a compiled bitmap to be up to three times slower than memcpy().
Test approach
I wrote a test program that blits three different images, at three different sizes, using each of three different methods. The images were the standard OS X Stones background image, an image with random pixels generated via random(), and a solid blue image. I blit (blitted?) to the screen using the CGDirectDisplay API, and repeated the tests to an in-memory buffer. The blitters were a memcpy() driven blitter, a bitmap compiler, and (for the screen only) the draw method of an NSBitmapImageRep. In each case, I blit 50,000 times and timed the number of seconds it took. Division gives the frames per second, and multiplying by the number of pixels gives pixels per second.{kind=link}
Here is the Xcode project I wrote. I place it in the public domain. (Note that it outputs frames per second, not pixels per second. You can calculate pixels per second by multiplying the framerate by the number of pixels in a frame. Note that I lowered the test count to 500 from 50,000 so you don't tie up your computer for too long by accident. I also left in the stwu version of the compiler in case you're interested.)
Results
Here's what I got.
Pixels/second for blitting to memory:
|
Pixels/second for blitting to the screen:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Man, that's boring. All right, let's draw some graphs.
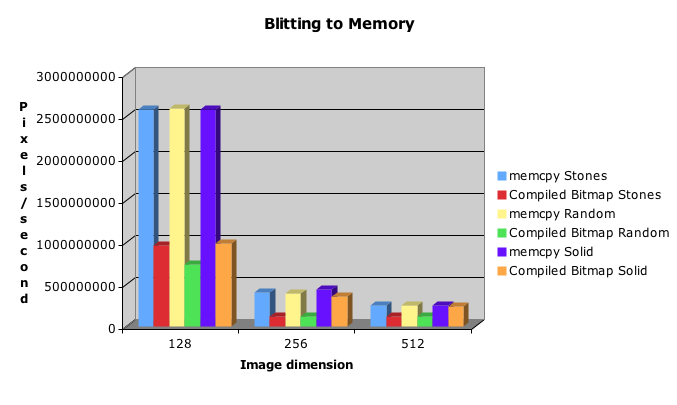
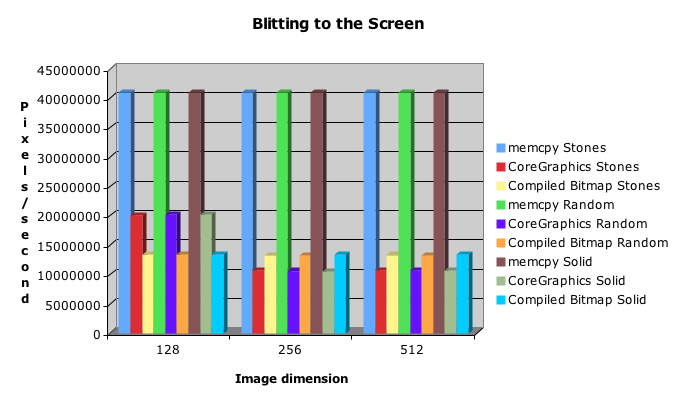
Count the digits...one...two...ok, yeah, note that the scales are very different here. We can blit two and a half billion pixels to memory in the same amount of time as it takes to blit forty million pixels to the screen.
So it's pretty obvious that memcpy() is faster than my bitmap compiler. The only point where my compiled bitmap is competitive is blitting a large solid color.
Ex Post Facto Explanation
Was my Latin right? Darn if I know. Anyways, I noticed that memcpy() is using a sequence of unrolled lvx and stvx instructions. That means Altivec acceleration! It may be part of the reason memcpy() is so fast. Unfortunately, the only way to fill a vector register with literal values is to assemble them in memory and then load them in, so it would not be easy to vectorize the bitmap compiler, except in special cases. The results might be somewaht different on an Altivec-lacking G3.
Blitting the solid image to memory via a compiled bitmap is between two and three times faster than the non-solid images, and is competitive with memcpy(), except in the 128x128 case. I don't know why memcpy() is so much faster in the 128x128 case. I also don't know why blitting to the screen is so much faster with memcpy() compared with the other techniques. If you know or have ideas, please comment on them!
It's also very likely that I've missed a major optimization opportunity. I'm far from a guru when it comes to the PowerPC. If you spot one, please post it in the comments!