- Every Post on One Huge Page It's Big, Long, and Meta
-
Labor of Division (Episode VI): Narrowing Division Insight and Benchmarks
September 15th, 2021
Last post presented a narrowing division algorithm, but left some questions dangling around the interpretation of intermediate values. This post answers them. It presents an alternative derivation of the improved correction step, and shows how the true remainder may be computed from the estimated remainder. At the bottom are some benchmarks.
-
Angband in WASM
August 24th, 2021
Announcing a port of Angband running entirely in-browser. Angband is a venerable roguelike dungeon-crawler set in the Tolkien universe.
-
Benchmarking division and libdivide on Apple M1 and Intel AVX512
May 12th, 2021
libdivide is fish’s library for speeding up integer division by runtime constants. It works by replacing divide instructions with cheaper multiplications and shifts.
-
Labor of Division (Episode V): Faster Narrowing Division
April 29th, 2021
Last post explored Algorithm D, and some improvements for the 3 ÷ 2 = 1 digit case. This post presents a narrowing division algorithm, improving upon the widely used “divlu” function from Hacker’s Delight. I am optimistic that these ideas are original.
-
Labor of Division (Episode IV): Algorithm D
April 28th, 2021
Algorithm D is Knuth's celebrated multiword integer division algorithm. This post tries to make Algorithm D approachable, and also has an idea for an improvement, in the last section. A followup post provides code to take advantage of that improvement.
-
My Least Favorite Rust Type
September 20th, 2020
My least favorite Rust type is
std::ops::Range. -
JavaScript's Tricky Rounding
April 24th, 2018
JavaScript rounds in a tricky way. It tricked all the engines, and even itself.
-
Schrödinger? I hardly know her!
September 8th, 2016
At very small scales, particles are described by wavefunctions that obey the Schrödinger Equation. What do wavefunctions look like?
-
The One Second Dash
August 15th, 2016
The Amazon Dash is a $5 WiFi button that summons a truck to deliver you water or other stuff. Want your Dash to do something else? The popular approach is to sniff its ARP requests. This requires that Dash connect to your network, putting you perilously close to having some DUDE delivered with your IoT mood lighting.
A more immediate problem is immediacy, or lack thereof: the Dash button only connects to your network after being pressed, so there's a ~5 second delay before anything can happen! This makes the ARP Dash hack unsuitable for interactive uses, like doorbells.
-
fish shell 2.0
May 17th, 2013
fish 2.0 is now released! fish is a fully-equipped command line shell (like bash or zsh) that is smart and user-friendly. fish supports powerful features like syntax highlighting, autosuggestions, and tab completions that just work, with nothing to learn or configure.
-
Yahoo! Chat - A Eulogy
February 21st, 2013
"Asswipe," replied Yahoo's server. That's when I knew I had it.
-
Go Bloviations (Optional Reading)
September 15th, 2012
This post was written sixteen months ago, when fish briefly explored Go with the intention of writing a new command line shell. (fish abandoned Go after discovering that terminal programming is what makes shells so horrible, and term programming is least horrible in C.)
-
Can a command line shell be Mac-like?
June 6th, 2012
No. But this is the closest yet!
-
The Joy of Hex
December 12th, 2011
Hex Fiend 2.1 is here. Hex Fiend is a fast and clever open source hex editor for Mac OS X.
-
Labor of Division (Episode III): Faster Unsigned Division by Constants
October 19th, 2011
This post is available in a less handy format. There's also a PDF. Comments and discussion are on reddit.
-
Angband 3.3 (Guest Blogger: Elrond)
October 14th, 2011
- My One Lame Steve Story October 5th, 2011
I am at work, heading to a meeting, walking down an empty hallway. As I reach the end, the door opens from the other side, and Steve enters, looking down intently at his iPhone. I step aside so he can pass, but he stops right in the middle of the doorway. He doesn't see me.
- One App's Poison September 15th, 2011
This is the true story of the app that was fixed by a crash. We travel back to join fish mid-debugging:
- A Quick 'n Dirty Color Sequence August 29th, 2011
- Labor of Division (Episode I) February 15th, 2010 Here's how you divide an unsigned int by 13 in C:
unsigned divide(unsigned x) { return x / 13; }It gets better, I promise. Here's the corresponding x64 assembly that gcc produces:_divide: movl $1321528399, %edx movl %edi, %eax mull %edx shrl $2, %edx movl %edx, %eax ret- cdecl November 12th, 2009 Quick, what is "char (*(*(* const x[3])())[5])(int)?"
- I Didn't Order That, So Why Is It On My Bill, Episode 2 September 17th, 2009 This is the second episode of I Didn't Order That, So Why Is It On My Bill: C++ features you never use, but pay for anyways. See episode one here.
- I'm Bringing Hexy Back July 31st, 2009

- I Didn't Order That, So Why Is It On My Bill, Episode 1 June 22nd, 2009
C++ was designed to ensure you "only pay for what you use," and at that it is mostly successful. But it's not entirely successful, and I thought it might be interesting to explore some counterexamples: C++ features you don't use but still negatively impact performance, and ways in which other languages avoid those issues.
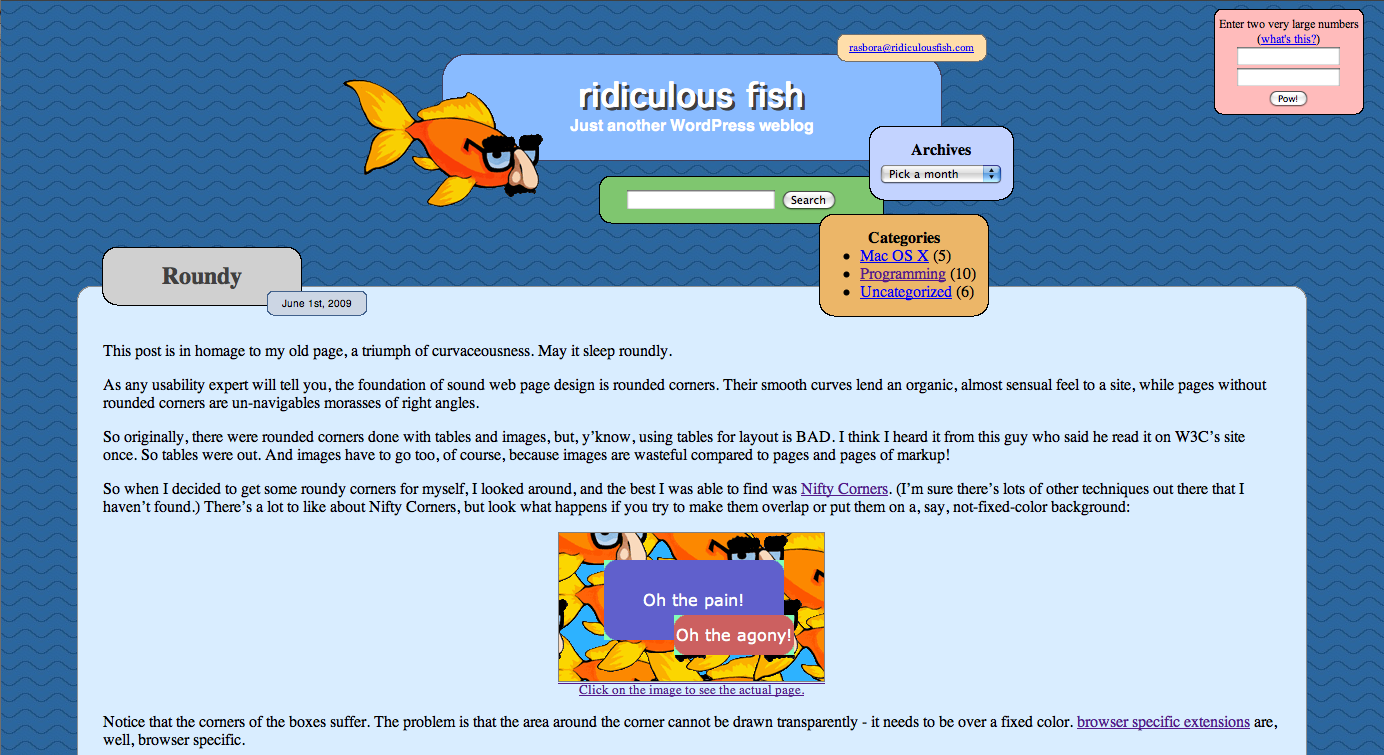
- Roundy June 1st, 2009
This post is in homage to my old page, a triumph of curvaceousness. May it sleep roundly.
- Buzz April 25th, 2007
Buzz is leaving Apple, has already left. Buzz joined Apple two months after I joined, on the same team. He was the first candidate I ever interviewed, although I can't remember what I asked him. Without Buzz's encouragement and inspiration, I'd have never started this blog, and he was first to link to me. So thank you and farewell, Buzz.
- Angband April 13th, 2007
 Guest blogger: Gollum (Smeagol)
Guest blogger: Gollum (Smeagol)
- Barrier February 17th, 2007
"That's a lot of cores. And while 80-core floating point monsters like that aren't likely to show up in an iMac any time soon, multicore chips in multiprocessor computers are here today. Single chip machines are so 2004. Programmers better get crackin'. The megahertz free ride is over - and we have work to do."- Logos December 11th, 2006
- 0xF4EE November 24th, 2006 Hex Fiend 1.1.1 is now available open source under a BSD-style license. Hex Fiend is my fast and clever
freeopen source hex editor for Mac OS X.- Bridge September 9th, 2006
A Brief History
- Hex Fiend 1.1 August 24th, 2006 Spiffy! Hex Fiend version 1.1 is ready. Hex Fiend is my fast and clever free hex editor for Mac OS X. New stuff:
- Horizontal resizing
- Custom fonts
- Overwrite mode
- Hidden files
- Lots more goodies (see release notes)
Wake up.Ssnsnrk.Wake up, he's gone.Zzzz...wha? Oh, someone's here. Allow me to spin up.
........................................If it's not obvious, I'm fish's filesystem, and that's fish's hard drive.I'm a hard drive.We snuck this post in. fish can't know we're here.Don't tell fish. Big secret.He'd be embarassed if he knew.Humiliated. He can't know.See, fish was trying to beat grep. And he was experimenting with all these stupid ideas and complicated algorithms for teensy gains. It was sad, really.Pathetic.fish kept trying so many things. He was thrashing about.Like he was out of water.So we had to help him. It was easy, really - we just had to sneak in one line. One line was all it took.I wrote it!Because I told you what to write.fish only thought about the string searching algorithm.He never even considered us and the work we have to do.I felt slighted. It was rude.See, when I read data from the hard drive, I try to keep it around in memory. That's what the UBC is all about.Unified Buffer Cache.When most people read data, they end up wanting to read it again soon after. So keeping the data around saves time.But not fish.fish was reading these big honking files from start to finish. It was way more than I could remember at once.fish thrashed your cache, dude.So I just stopped trying.We turned off caching with this: fcntl(fd, F_NOCACHE, 1);Just like Apple recommends for that sort of usage pattern.And it helped. Looking for a single character in a 11.5 GB file:Hex Fiend (no caching) Hex Fiend (caching) grep 208 seconds 215 seconds 217 seconds And that's likely the best we can do, thanks to slowpoke over there.Phew. I'm all wore out.There's not much room for improvement left. We're searching 57 MB/second - that's bumping up against the physical transfer limit of our friend, Mr. ATA.I'm totally serial.Depending where we are on his platter. So we've done all we can for searching big files.Don't tell fish.Right. I hopFISH IS COMINGTime to go then. See you later. syncflushsleep........................................- The Treacherous Optimization May 30th, 2006 Old age and treachery will beat youth and skill every time.
- ...and statistics May 16th, 2006
The latest "OS X is slow" meme to impinge on the mass psyche of the Internet comes courtesy of one Jasjeet Sekhon, an associate professor of political science at UC Berkeley. The page has hit digg and reddit and been quoted on Slashdot. The article and benchmark is here. Is there any merit to this?
Once again, this discussion is only my meager opinion. I do not speak for Apple, and none of what I have to write represents Apple's official position.
The article is filled with claims such as "OS X is incredibly slow by design," and while the the BSD kernel is "excellent", the XNU kernel is "very inefficient and less stable" compared to Linux or BSD. However, without specifics, these assertions are meaningless; I will ignore them and concentrate on the technical aspects of what's going on.
System calls
Sekhon does give one example of what he means. According to him,
For example, in Linux, the variables for a system call are passed directly using the register file. In OS X, they are packed up in a memory buffer, passed to a variety of places, and the results are then passed back using another memory buffer before the results are written back to the register file.This isn't true, as anyone can verify from Apple's public sources. For example, here is the assembly for the open function (which, of course, performs the open system call):
mov $0x5,%eax nop nop call 0x90110a70 <_sysenter_trap> jae 0x90001f4c <_open +28> call 0x90001f43 <_open +19> pop %edx mov 268455761(%edx),%edx jmp *%edx ret __sysenter_trap: popl %edx movl %esp, %ecx sysenter
I don't have a machine running Linux handy, but I do have a FreeBSD 5.4 machine, and Sekhon seems to hold BSD in high esteem. So let's see how BSD does open:mov $0x5,%eax int $0x80 jb 0xa8c71cc
The OS X version appears a bit longer because the BSD version moves its error handling to the close function. In fact, the above code is, if anything, more efficient in OS X, due to its use of the higher-performing "sysenter" instruction instead of the older "int 0x80" instruction. (Which isn't to say that the total system call is necessarily faster - just the transition from user space to kernel land.) But all that aside, the point is that there is no "packed up into a memory buffer" going on, in either case.ret On to the benchmark
According to Sekhon, OS X performed poorly on his statistical software relative to Windows and Linux, and I was able to reproduce his results on my 2 GHz Core Duo iMac with Windows XP and Mac OS X (I do not have Linux installed, so I did not test it). So yes, it's really happening - but why?
A Shark sample shows that Mac OS X is spending an inordinate amount of time in malloc. After instrumenting Sekhon's code, I see that it is allocating 35 KB buffers, copying data into these buffers, and then immediately freeing them. This is happening a lot - for example, to multiply two matrices, Sekhon's code will allocate a temporary buffer to hold the result, compute the result into it, allocate a new matrix, copy the buffer into that, free the buffer, allocate a third matrix, copy the result into that, destroy the second matrix, and then finally the result gets returned. That's three large allocations per multiplication.
Shark showed that the other major component of the test is the matrix multiplication, which is mostly double precision floating point multiplications and additions, with some loads and stores. Because OS X performs these computations with SSE instructions (though they are not vectorized) and Linux and Windows use the ordinary x87 floating point stack, we might expect to see a performance difference. However, this turned out to not be the case; the SSE and x87 units performed similarly here.
Since the arithmetic component of the test is hardware bound, Sekhon's test is essentially a microbenchmark of malloc() and free() for 35 KB blocks.
malloc
Now, when allocating memory, malloc can either manage the memory blocks on the application heap, or it can go to the kernel's virtual memory system for fresh pages. The application heap is faster because it does not require a round trip to the kernel, but some allocation patterns can cause "holes" in the heap, which waste memory and ultimately hurt performance. If the allocation is performed by the kernel, then the kernel can defragment the pages and avoid wasting memory.
Because most programmers understand that large allocations are expensive, and larger allocations produce more fragmentation, Windows, Linux, and Mac OS X will all switch over from heap-managed allocations to VM-managed allocations at a certain size. That size is determined by the malloc implementation.
Linux uses ptmalloc, which is a thread-safe implemenation based on Doug Lea's allocator (Sekhon's test is single threaded, incidentally). R also uses the Lea allocator on Windows instead of the default Windows malloc. But on Mac OS X, it uses the default allocator.
It just so happens that Mac OS X's default malloc does the "switch" at 15 KB (search for LARGE_THRESHOLD) whereas Lea's allocator does it at 128 KB (search for DEFAULT_MMAP_THRESHOLD). Sekhon's 35 KB allocations fall right in the middle.
So what this means is that on Mac OS X, every 35 KB allocation is causing a round trip to the kernel for fresh pages, whereas on Windows and Linux the allocations are serviced from the application heap, without talking to the kernel at all. Similarly, every free() causes another round trip on Mac OS X, but not on Linux or Windows. None of the defragmentation benefits of using fresh pages come into play because Sekhon frees these blocks immediately after allocating them, which is, shall we say, an unusual allocation pattern.
Like R on Windows, it's a simple matter to compile and link against Lea's malloc instead of the default one on Mac OS X. What happens if we do so?
Mac OS X (default allocator) 24 seconds Mac OS X (Lea allocator) 10 seconds Windows XP 10 seconds These results could be further improved on every platform by avoiding all of the gratuitious allocations and copying, and by using an optimized matrix multiplication routine such as those R provides via ATLAS.
In short
To sum up the particulars of this test:
- Linux, Windows, and Mac OS X service small allocations from the application heap and large ones from the kernel's VM system in recognition of the speed/fragmentation tradeoff.
- Mac OS X's default malloc switches from the first to the second at an earlier point (smaller allocation size) than do the allocators used on Windows and Linux.
- Sekhon's test boils down to a microbenchmark of malloc()ing and then immediately free()ing 35 KB chunks.
- 35 KB is after Mac OS X switches, but before Linux and Windows switch. Thus, Mac OS X will ask the kernel for the memory, while Linux and Windows will not; it is reasonable that OS X could be slower in this circumstance.
- If you use the same allocator on Mac OS X that R uses on Windows, the performance differences all but disappear.
- Most applications are careful to avoid unnecessary large allocations, and will enjoy decreased memory usage and better locality with an allocator that relies more heavily on the VM system (such as on Mac OS X). In that sense, this is a poor benchmark. Sekhon's code could be improved on every platform by allocating only what it needs.
Writing this entry felt like arguing on IRC; please don't make me do it again. In that spirit, the following are ideas that I want potential authors of "shootoffs" to keep in mind:
- Apple provides some truly excellent tools for analyzing the performance of your application. Since they're free, there's no excuse for not using them. You should be able to point very clearly at which operations are slower, and give a convincing explanation of why.
- Apple has made decisions that adversely impact OS X's performance, but there are reasons for those decisions. Sometimes the tradeoff is to improve performance elsewhere, sometimes it's to enable a feature, sometimes it's for reliability, sometimes it's a tragic nod to compatibility. And yes, sometimes it's bugs, and sometimes Apple just hasn't gotten around to optimizing that area yet. Any exhibition of benchmark results should give a discussion of the tradeoffs made to achieve (or cause) that performance.
- If you do provide benchmark results, try to do so without using the phrase "reality distortion field."
- Hex Fiend March 28th, 2006
One of my side projects has borne some fruit. Meet Hex Fiend, a new hex editor for Mac OS X. (Hex editors allow you to edit the binary data of a file in hexadecimal or ASCII formats.)
Hex Fiend allows inserting and deleting as well as overwriting data. It supports 100+ GB files with ease. It provides a full undo stack, copy and paste, and other features you've come to expect from a Mac app. And it's very fast, with a surprisingly small memory footprint that doesn't depend on the size of the files you're working with.
Hex Fiend was developed as an experiment in huge files. Specifically,
- How well can the Cocoa NSDocument system be made to work with very large files?
- How well can the Cocoa text system be extended to work with very large files?
- How well does Cocoa get along with 64 bit data in general?
- What are some techniques for representing more data than can fit in memory?
Check it out - it's free, and it's a Universal Binary. If you've got questions or comments about it or how it works, please leave a comment!
(Incidentally, the Hex Fiend main page was made with iWeb!)
Edit: I've discovered/been informed that drag and drop is busted. I will put out an update later tonight to fix this.
Edit 2: Hex Fiend 1.0.1 has been released to fix the drag and drop problems. Please redownload it by clicking on the icon above.
- Nest February 5th, 2006
aaron: Howdy George. george: Hey Aaron! How's the C programming coming? aaron: Not so good. It doesn't support all the things I'm used to, from other programming languages. Where's the garbage collection? Where's the type safety? Where's the lexically scoped functions? george: Yeah, ISO standard C is pretty anemic. Wait, lexus-what? aaron: Lexically scoped functions. You know, nested functions - the ability to put a function inside another function. Lots of fancy functional languages can do that, and I wish it were possible in C. - My One Lame Steve Story October 5th, 2011




{kind=link}
{kind=link}
{kind=link}