Last post presented a narrowing division algorithm, but left some questions dangling around the interpretation of intermediate values. This post answers them. It presents an alternative derivation of the improved correction step, and shows how the true remainder may be computed from the estimated remainder. At the bottom are some benchmarks.
Extending credit for the essential observation to Colin Bartlett who spotted that divllu was effectively computing a (potentially negative) remainder, represented as a difference of two non-negative uints. Thanks Colin!
A quick recap: we wish to write a function that divides a 128-bit uint by a 64-bit uint, producing a 64-bit quotient and remainder. We conceive of this as dividing a 4 digit number by a 2 digit number to produce a 2 digit quotient and remainder, where a digit is base 232. Call that 4÷2 → 2. Grade school long division (see this post) reduces the problem to 3÷2 → 2. That’s still too big for our 64-bit hardware divider, so we estimate the quotient using a 2÷1 → 2 divide, and then “correct” the estimate, achieving 3÷2 → 2. The correction step is the focus; the idea here is we can also extract the remainder from the correction.
Theory
Working base 232, we have a 3 digit dividend $ {n_2 n_1 n_0} $, and 2 digit divisor $ {d_1 d_0} $. We wish to divide them: $q = \lfloor \tfrac {n_2 n_1 n_0} {d_1 d_0} \rfloor $. We estimate $ \hat{q} = \lfloor \tfrac {n_2 n_1} {d_1} \rfloor $, which can be computed by hardware. We know that q̂ exceeds q by no more than 2 (having normalized).
Start by computing the corresponding remainder $ \hat{r} = {n_2 n_1} - \hat{q} \times d_1 $. (Hardware often provides this “for free” alongside the quotient.) Note this “remainder of the estimate” does NOT approximate the true remainder.
Now the true remainder will be negative if and only if the estimated quotient is too big. For example, if we estimate 13 ÷ 3 ≅ 5, we will compute a remainder of 13 - 3×5 = -2. So if $\hat{q}$ is bigger than the true quotient $q$, the computed remainder $ r = {n_2 n_1 n_0} - \hat{q} \times {d_1 d_0} $ will be negative. Sadly we cannot directly perform this subtraction, because tons of stuff will overflow, but we can avoid overflow by “factoring out” the initial estimate. Apply some algebra:
where $ b $ is our digit base 232. These two terms correspond to c2 and c1 from last post, only now we can provide a proper interpretation:
$ \hat{r} \times b + n_0 $ is the remainder neglecting the low divisor digit, i.e. assuming that digit is 0.
$ \hat{q} \times {d_0} $ is the remainder contribution from the low divisor digit.
As for names, perhaps remd1 and remd0, as these two quantities reflect the contribution to the remainder from each divisor digit.
This leads immediately to the conclusion that $ remd1 - remd0 $ yields the true remainder, after correcting it similarly to how we correct the quotient. This reverses the second question and answers in the affirmative: we can compute the true remainder using the estimated remainder. This in turn reveals a potential optimization, of subtracting instead of multiplying. Is it faster?
Code
Recall the correction step from last post, including remainder computation:
Even though we have “saved” a multiply, this benchmarks slower! The reason is that the compiler now emits a branch, which is mispredicted for 5% of random inputs (according to perf).
We can partially rescue the idea through branchless tricks:
libdivide subtract branchless
c1=qhat*den0;c2=rhat*b+num1;remd=c2-c1;qexcess1=-(remd>c2);// -1 if c1 > c2qexcess2=qexcess1&(-remd>den);// 1 if c1 - c2 > denqhat+=qexcess1;qhat-=qexcess2;remainder=remd+(den&qexcess1)<<qexcess2;
This is competitive with the “multiply” version, yet harder to follow. Multiplies are cheap.
Benchmarks
A little microbenchmark: create a sequence of 16k random dividend/divisor pairs, and then measure the time to compute and sum all quotients and remainders. This is repeated 1k times with the same sequence, and the best (fastest) result for each algorithm is kept.
x86-64 has a narrowing divide instruction divq and we throw that into the mix. Times are nanoseconds per divide, lower is better.
CPU
Hackers Delight
libdivide mul
libdivide sub
libdivide sub branchless
hardware divq
Intel i7-8700
23.5
18.6
21.2
18.2
19.7
Intel Xeon 8375C
17.2
10.0
14.2
11.5
2.9
Apple M1 Mac Mini
10.4
4.7
9.6
5.4
N/A
Sadly no real speedup from this technique.
Amusingly the best software implementation narrowly beats divq on Coffee Lake (and probably earlier). This instruction is much faster on the Ice Lake Xeon; here’s why!
If you wish to run this yourself, the (messy) code is here:
You really can compute the remainder directly by subtracting the two correction terms! This is a neat insight. Unfortunately it did not produce a consistent speedup, so the reference algorithm (aka “libdivide mul”) won’t change. If you have a narrowing divide, consider upgrading from the version in Hacker’s Delight to the libdivide reference, which is both faster and clearer.
There’s no sign-up or other nonsense. Some screenshots:
Click on Unleash the Borg and watch it go. Click on Turbo and watch it go faster!
This port compiles Angband to WASM using Emscripten. It uses a new front end not based on SDL or curses, but instead targeting vanilla JS and HTML. The WASM code runs in a web worker, and communicates with the main thread to receive events and issue rendering commands. Text and graphics are drawn via an HTML table element. JS logic is in TypeScript. Savefiles use IndexedDB.
This is the old Angband v3.4.1, specifically to support the automated Angband player, aka the Borg. I hope to port to latest Angband and upstream this as a new front-end.
If you want to get involved, here’s the GitHub repo, it’s easy to get started, really fun, and there’s lots to do!
libdivide is fish’s library for speeding up integer division by runtime constants. It works by replacing divide instructions with cheaper multiplications and shifts.
libdivide supports SIMD, and recently gained support for AVX-512 and ARM NEON. Let’s benchmark on an Intel Xeon and Apple’s M1.
Test Setup
The microbenchmark is a sum-of-quotients function, like:
uint32_tsumq(constuint32_t*vals,size_tcount,uint32_td){uint32_tsum=0;for(size_ti=0;i<count;i++)sum+=vals[i]/d;// this division is the bottleneckreturnsum;}
The execution time of this function is dominated by the divide. It may be optimized with libdivide:
This is typically 2-10x faster, depending on d and count. It also unlocks vectorization for even more speedup - example.
The times below measure the above loop with d=7 (a “slow case”) and count=524k. The loop is repeated 30 times, and the best (fastest) result is kept. 1
Intel Xeon 3.0 GHz (8275CL)
Times are nanoseconds per divide, and a percentage improvement compared to hardware (i.e. udiv instruction). Lower is better.
width
hardware
libdivide scalar
libdivide SSE2
libdivide AVX2
libdivide AVX512
u32
2.298
0.872 (-62%)
0.355 (-84%)
0.219 (-90%)
0.210 (-91%)
u64
6.998
0.891 (-87%)
1.058 (-85%)
0.574 (-92%)
0.492 (-93%)
The three vector ISAs are similar except for width: 128, 256, 512 bits.
AVX512 is twice the width of AVX2 but only marginally faster. Speculatively, AVX512 processes multiplies serially, one 256-bit lane at a time, losing half its parallelism.
libdivide must use 32x32->64 muls (mul_epu32) for vectorized 64 bit, incurring the 4x penalty 2. We would expect to break even at AVX2, which has 4x parallelism; instead AVX2 is faster than scalar, perhaps because a 32 bit multiply is faster than 64 bit.
Apple M1 3.2 GHz (Mac Mini)
Times are nanoseconds per divide; lower is better.
width
hardware
libdivide scalar
libdivide NEON
u32
0.624
0.351 (-43%)
0.158 (-75%)
u64
0.623
0.315 (-49%)
0.555 (-11%)
The M1 is 10x faster than the Xeon at 64 bit divides. It’s…just wow.
The hardware division time of 0.624 nanoseconds is a clean multiple of 3.2 GHz, suggesting a throughput of 2 clock cycles per divide. That is remarkable: hardware dividers are typically variable-latency and hard to pipeline, so 30+ clock cycles per divide is common. Does the M1 have more than one integer division unit per core?
Amusingly, scalar 64 bit is faster than scalar 32 bit. This is because AARCH64 has a dedicated instruction for 64 bit high multiplies (umulh), while 32 bit high multiplies are performed with a 64 bit low multiply (umull), followed by a right shift.
NEON with u32 allows four 32-bit high-multiplies with only two umull instructions (godbolt). So NEON u32 should be nearly twice as fast as scalar; in fact it is even faster, probably because of amoritized fixed costs (branches, etc).
NEON with u64 is slower because its multiplier is not wide enough, so it incurs the 4x penalty 2, and its skinny vector only offers 2x parallelism. (Nevertheless it still may be useful as part of a larger sequence, to keep data in vector registers.)
Conclusions and unanswered questions
libdivide is still quite effective at speeding up integer division, even with the M1’s fast divider. Vectorization greatly improves 32 bit, and is a mixed bag for 64 bit, but still faster than hardware.
Some questions:
Why is AVX512 only slightly faster than AVX2? Are the umuls are serialized per-lane, is it downclocking?
How is Apple M1 able to achieve a throughput of .5 divides per cycle? Is the hardware divider pipelined, is there more than one per core?
Thanks for reading!
Notes
The results were collected using libdivide’s benchmark tool. You can run it yourself:
git clone https://github.com/ridiculousfish/libdivide.git
mkdir libdivide/build && cd libdivide/build
cmake .. && make benchmark
./benchmark u32 # or u64 or s32 or s64
7 is a “slow case” for libdivide, because 7’s magic number must be 33 or 65 bits, and so cannot fit in a register. This is as slow as libdivide gets. ↩
To divide a 64 bit number, libdivide needs the high half of a 64 bit product, a so-called high multiply. Unfortunately SIMD hardware typically has a 53-bit multiplier: just big enough for double-precision floating point, not big enough for libdivide. So libdivide must cobble together a 64-bit high-multiply through four 32x32->64 multiplies. This incurs a factor-of-4 penalty for 64 bit vectorized division on SIMD. ↩↩2
Last post explored Algorithm D, and some improvements for the 3 ÷ 2 = 1 digit case. This post presents a narrowing division algorithm, improving upon the widely used “divlu” function from Hacker’s Delight. I am optimistic that these ideas are original.
divlu is a narrowing division: it divides a 4 digit number by a 2 digit number, producing a 2 digit quotient and remainder. This is achieved by specializing Algorithm D for 4-digit dividend and 2-digit divisor.
q̂ is an estimated quotient digit. It is quite close to the quotient digit q; it may be exactly the same, or larger by 1 or 2, and that’s all! The tricky parts of divlu is “correcting” q̂ to the true digit, by subtracting 0, 1, or 2.
Note this is used twice, once for each quotient digit. There are three improvements possible here:
Unroll the loop, whose trip count is at most 2
divlu loops until the digit is correct, but we know that q̂ may exceed q by no more than 2. So just correct q̂ at most twice, saving some arithmetic and a branch.
The final Algorithm D is somewhat vague here: it says to merely “repeat the check”, and it is not obvious from the text if you need to repeat it once or infinite times. A conservative reading suggests that you need a loop, but we know that twice is enough.
Omit the checks for q̂ >= b
If q̂ >= b, then the estimated quotient requires more than one digit; that means our estimate is certainly too big, because the true quotient is single-digit.
This check is necessary in Knuth but an optimization at best in divlu. To understand why, consider dividing (base 10) something like 100000 / 10001. Algorithm D will start by dividing a two digit prefix of the dividend by the first digit of the divisor: 10 / 1, and then correct it with the next divisor digit (0, does nothing). This estimates the first quotient digit as 10 (obviously absurd, 10 is not a digit!). It’s only very much later, as the algorithm traverses the divisor, that it discovers the 1 at the end, and finally decrements the 10 to 9 (the “add back” phase). But in the interim, 10 was too large to store in our digit array, so we might as well decrement it right away, and save ourselves the trouble later.
But in divlu there is no “add back” phase needed, because each quotient digit is informed by the entire divisor (a mere two digits). Furthermore, as digits are half a machine word, there is no challenge with storing a two-digit quantity. Thus the check for q̂ >= b is redundant with the next check; in rare cases it saves a multiply but is surely a loss.
You may worry that the check is necessary to prevent overflow in the q1*vn0 calculation, but analysis shows this cannot overflow as q1 <= b + 1 (see the last section in the previous post).
Avoid overflow checks
We may decrement q̂ twice at most. Knuth gives the cryptic suggestion of “repeat this test if r̂ < b” and Hackers Delight implements this faithfully:
if(rhat<b)gotoagain;
Why compare r̂ < b? In the next iteration we compute b ⨯ r̂ and compare that to a (at most) two-digit number. So if r̂ ≥ b we can certainly skip the comparison: it is sufficient. But the test is only necessary in a practical sense, to avoid risking overflow in the b ⨯ r̂ calculation. If we rearrange the computation as in the previous post, we no longer risk overflow, and so can elide this branch.
Put them together
Now we have improved the quotient correction by reducing the arithmetic and branching:
What is the proper interpretation of c1 and c2? I can’t name these well, as I lack intuition about what they are.
Can we correct q̂ using the true remainder? We know that q̂ - 2 ≤ q. If we compute the remainder for q̂ - 2, multiply it by the divisor, and check how many times to add the divisor until it would exceed the dividend - this would also correct q while simultaneously calculating the remainder. The main difficulty here is that the dividend is three digits, so there is no obvious efficient way to perform this arithmetic. But if we could, it would save some intermediate calculations.
Final code
This presents an optimized 128 ÷ 64 = 64 unsigned division. It divides a 128 bit number by a 64 bit number to produce a 64 bit quotient.
Reference code is provided as part of libdivide. This particular function is released into the public domain where applicable, or the CC0 Creative Commons license at your option.
Fun fact: this function found a codegen bug in LLVM 11! (It had already been fixed in 12.)
/*
* Perform a narrowing division: 128 / 64 -> 64, and 64 / 32 -> 32.
* The dividend's low and high words are given by \p numhi and \p numlo, respectively.
* The divisor is given by \p den.
* \return the quotient, and the remainder by reference in \p r, if not null.
* If the quotient would require more than 64 bits, or if denom is 0, then return the max value
* for both quotient and remainder.
*
* These functions are released into the public domain, where applicable, or the CC0 license.
*/uint64_tdivllu(uint64_tnumhi,uint64_tnumlo,uint64_tden,uint64_t*r){// We work in base 2**32.// A uint32 holds a single digit. A uint64 holds two digits.// Our numerator is conceptually [num3, num2, num1, num0].// Our denominator is [den1, den0].constuint64_tb=(1ull<<32);// The high and low digits of our computed quotient.uint32_tq1;uint32_tq0;// The normalization shift factor.intshift;// The high and low digits of our denominator (after normalizing).// Also the low 2 digits of our numerator (after normalizing).uint32_tden1;uint32_tden0;uint32_tnum1;uint32_tnum0;// A partial remainder.uint64_trem;// The estimated quotient, and its corresponding remainder (unrelated to true remainder).uint64_tqhat;uint64_trhat;// Variables used to correct the estimated quotient.uint64_tc1;uint64_tc2;// Check for overflow and divide by 0.if(numhi>=den){if(r!=NULL)*r=~0ull;return~0ull;}// Determine the normalization factor. We multiply den by this, so that its leading digit is at// least half b. In binary this means just shifting left by the number of leading zeros, so that// there's a 1 in the MSB.// We also shift numer by the same amount. This cannot overflow because numhi < den.// The expression (-shift & 63) is the same as (64 - shift), except it avoids the UB of shifting// by 64. The funny bitwise 'and' ensures that numlo does not get shifted into numhi if shift is 0.// clang 11 has an x86 codegen bug here: see LLVM bug 50118. The sequence below avoids it.shift=__builtin_clzll(den);den<<=shift;numhi<<=shift;numhi|=(numlo>>(-shift&63))&(-(int64_t)shift>>63);numlo<<=shift;// Extract the low digits of the numerator and both digits of the denominator.num1=(uint32_t)(numlo>>32);num0=(uint32_t)(numlo&0xFFFFFFFFu);den1=(uint32_t)(den>>32);den0=(uint32_t)(den&0xFFFFFFFFu);// We wish to compute q1 = [n3 n2 n1] / [d1 d0].// Estimate q1 as [n3 n2] / [d1], and then correct it.// Note while qhat may be 2 digits, q1 is always 1 digit.qhat=numhi/den1;rhat=numhi%den1;c1=qhat*den0;c2=rhat*b+num1;if(c1>c2)qhat-=(c1-c2>den)?2:1;q1=(uint32_t)qhat;// Compute the true (partial) remainder.rem=numhi*b+num1-q1*den;// We wish to compute q0 = [rem1 rem0 n0] / [d1 d0].// Estimate q0 as [rem1 rem0] / [d1] and correct it.qhat=rem/den1;rhat=rem%den1;c1=qhat*den0;c2=rhat*b+num0;if(c1>c2)qhat-=(c1-c2>den)?2:1;q0=(uint32_t)qhat;// Return remainder if requested.if(r!=NULL)*r=(rem*b+num0-q0*den)>>shift;return((uint64_t)q1<<32)|q0;}
Algorithm D is Knuth's celebrated multiword integer division algorithm. This post tries to make Algorithm D approachable, and also has an idea for an improvement, in the last section. A followup post provides code to take advantage of that improvement.
To build intuition, we'll use concrete base-10 values, instead of a general base and digit count like Knuth does. It should be straightforward to generalize to arbitrary bases and digit counts.
The problem is dividing one big number by another big number. The numbers are big enough to require multiple "digits", where a digit is a number in some comfortable base. The examples will be base 10, but in practical applications the base is the width of a hardware divider, or sometimes half that. For example, when dividing a 256-bit number by a 128-bit number, we may pick 64-bit digits, for a base of $2^{64}$, which is huge.
It's hard to beat grade-school long division. In long division, we crank out the quotient digits from left to right by peeling off a prefix of the numerator, dividing that, and then using the remainder in the next step. For example:
Compute 1793 ÷ 25. Start with the first three digits of the dividend, i.e. 179.
179 ÷ 25 = 7, remainder 4. Our first quotient digit is 7.
Take the remainder and append ("bring down") the next digit 3 to form a new dividend 43.
43 ÷ 25 = 1, remainder of 18.
Full quotient is 71 with remainder of 18.
Our dividend was four digits, but through long division we only had to divide a three digit number. This is the general irreducible step in long division: if our divisor is N digits, we must work in N+1 digit chunks from the dividend. So our simplified problem is to compute $ q = \lfloor \tfrac n d \rfloor $, where n has exactly one more digit than d, and q is a single digit. (If q were not a single digit, then we peeled off too much of the dividend; back up one digit and try again.)
Now we switch to a sub-algorithm for this simpler problem.
We have an N digit denominator and an N+1 digit numerator; the quotient q is a single digit. How do we find it?
The big idea is to "zero out" the low digits: keep top two from the numerator, and top one from the denominator. For example, instead of $\lfloor \tfrac {2356} {395} \rfloor$, compute $\lfloor \tfrac {2300} {300} \rfloor$, which is the same as $\lfloor \tfrac {23} {3} \rfloor$, which is easy. We hope that this new "estimate" quotient, q̂ will be close to q, and so help us find q:
We'll try to make q̂ smaller than q. (Spoiler: we can't.)
If we want q̂ < q, then this zeroing process must make the quotient smaller. Let's arrange for the numerator to be reduced as much as possible (lots of 9s) and the denominator not at all (lots of zeros). For example $ \lfloor \tfrac {2399} {300} \rfloor $ has a good chance of making q̂ too small. Apply some algebra:
Now what is the fractional contribution of the two terms in the last expression? The first term can contribute at most 2/3, and the second at most 99/300, which is less than 1/3. So their sum is always less than 1, so it is always wiped out by the floor, and we have:
(This is surprising because it's not true with ordinary division: obviously for example $\tfrac {9999} {100} \gt \tfrac {9900} {100} $. It's true in integer division because of the floor.)
Now let's reverse it: make this zeroing process increase the quotient by as much as possible. What if the numerator ends in 0s (so it doesn't shrink) and the denominator end in lots of 9s (so it gets much smaller)? Like:
q̂ is a terrible estimate. When we zeroed out the denominator, we reduced it by nearly half, because its leading digit was 1. If the leading digit were larger, then zeroing out the rest wouldn't affect its value so much.
Let's bound the error using that leading digit. We will just call the numerator $ n $, and the denominator has leading digit $ v $ (following Knuth), where $ 0 \lt v \lt 10 $. We hope to maximize the error, so arrange for the numerator to have trailing 0s and the denominator trailing 9s. Examine the difference:
$ \hat{q} - q = \lfloor \tfrac n {v000} \rfloor - \lfloor \tfrac n {v999} \rfloor $
If we eliminate the floors, the fractional difference is always less than 1 (perhaps less than 0), so we have:
$ \hat{q} - q \lt \tfrac n {v000} - \tfrac n {v999} + 1 $
Apply some algebra to the difference of fractions:
$$\begin{align} \tfrac n {v000} - \tfrac n {v999} & = \tfrac {n \times {v999} - n \times {v000}} {v000 \times v999} \\[2ex]
& = \tfrac { n \times ( v999 - v000 ) } {v000 \times v999} \\[2ex]
& = \tfrac { n \times 999 } {v000 \times v999} \\[2ex]
& = \tfrac {999} {v000} \times \tfrac n {v999} \\[2ex]
& \lt \tfrac {1} {v} \times \tfrac n {v999} \\[2ex]
& \lt \tfrac {1} {v} \times 10 \\[2ex]
\end{align} $$
The last step used the fact that the quotient q is a single digit.
Inserting this, we get the relation:
$ \hat{q} - q \lt \tfrac n {v000} - \tfrac n {v999} + 1 \lt \tfrac {10} v + 1$
So when our denominator's leading digit is 1, q̂ may be too big by as much as 11! But if the leading digit were, say, 8, then q̂ is at most 2 too big.
Now for the trick: we can always arrange for the denominator to have a leading digit of 5 or more, by just multiplying it. If our denominator has a leading digit of, say, 4, just multiply the whole denominator by 2. And then multiply the numerator by 2 also, to keep the quotient the same.
Let's work an example:
$$ q = \lfloor \tfrac {192} {29} \rfloor = 6 \\[2ex]
\hat{q} = \lfloor \tfrac {190} {20} \rfloor = 9
$$
q̂ is a bad estimate because the denominator has a low leading digit of 2. So multiply top and bottom by 3 first:
$$q = \lfloor \tfrac {192} {29} \rfloor = \lfloor \tfrac {192 \times 3} {29 \times 3} \rfloor = \lfloor \tfrac {576} {87} \rfloor = 6 \\
\hat{q} = \lfloor \tfrac {570} {80} \rfloor = \lfloor \tfrac {57} {8} \rfloor = 7
$$
and our estimate q̂ is closer.
Increasing the leading digit of the divisor is the "normalization" step. After normalizing, the leading digit of at least 5 implies that $ \hat{q} - q \lt \tfrac {10} 5 + 1 = 3 $. And as q̂ and q are integral, we get the awesome result that $ \hat{q} - q \le 2 $. This normalization step ensures our estimate is off by at most 2!
Note that normalizing increases the leading digit of the divisor but does not add a new digit. Alas, it may add a new digit for the dividend, if you normalize before entering the long division algorithm (and you typically do). Also note that while normalizing does not affect the quotient, it does affect the remainder, which must be scaled down by the normalization factor.
Now that we have an estimated quotient digit, we proceed prosaically as in long division. Multiply the divisor by the quotient digit and subtract to produce a partial remainder. Slap on the next digit of the dividend ("bring down the...") and that is your new dividend.
If we over-estimated the quotient digit, we may get a negative remainder. For example, when the divisor is "just barely" larger than some factor of the dividend:
$$
q = \lfloor \tfrac {8000} {4001} \rfloor = 1 \\
\hat{q} = \lfloor \tfrac {8} {4} \rfloor = 2 \\
r = 8000 - \hat{q} \times {4001} \lt 0
$$
Whoops, but it's no problem: just decrement our quotient, and add back the divisor, until the remainder is no longer negative. But as we are performing multiword arithmetic, we should try to avoid these expensive extra computations. It would be better to correct the estimated quotient digit immediately.
Here we'll restrict ourselves to dividing a 3 digit dividend by a 2 digit divisor, producing a 1 digit quotient. We will see how to rapidly correct the error in q̂.
In this section, think of a "digit" as half of a machine word. Working with a two digit number is fast, but three or more digits is slow. "Overflow" means "requires more than two digits."
As proven above, we know that (after normalization) q̂ may exceed q by at most 2. Let's return to our previous example, and then extend it by computing a remainder r̂:
r̂ is "the remainder of the estimated quotient". It is NOT an estimate of the actual remainder; it has nothing whatsoever to do with the actual remainder, because we ignored the low digit of the divisor. This is true even if the estimated quotient digit is precise. In this sense "r-hat" is a poor choice of symbol, but we'll keep it for continuity with Knuth.
Now our quotient digit 7 is too high, but let's pretend we didn't know that and see what happens:
$$\begin{array}{r}7\\
87\enclose{longdiv}{576}\\
-\underline{609}\\
{\color{red}{?}}
\end{array}$$
The actual remainder would be negative. But to discover that, we had to perform an expensive full multiply (7 x 87) which produces 3 digits. We can avoid that full multiply with r̂:
$$
\hat{q} \times 87 \gt 576 \implies \\
\hat{q} \times 80 + \hat{q} \times 7 \gt 576 \implies \\
\hat{q} \times 80 + \hat{r} + \hat{q} \times 7 \gt 576 + \hat{r} \implies \\
570 + \hat{q} \times 7 \gt 576 + \hat{r} \implies \\
\hat{q} \times 7 \gt 6 + \hat{r}
$$
So take our estimated quotient digit, multiply it by the last digit in the divisor, and compare that to the sum of the the last digit of the dividend and the "remainder of the estimated quotient". If it's larger, subtract one from the estimated quotient and repeat. But note we only have to test this two times.
This explains the (otherwise baffling) comparison step in Algorithm D.
One last question: now that we have the correct quotient digit, don't we have to perform that widening multiply anyways to compute the remainder? The answer is no: the remainder is guaranteed to fit in two digits, so we can just use ordinary wrapping arithmetic to find it. For example, the first quotient digit is 6, so the first remainder is $ 576 - 6 \times 87 = 54 $; let's wrap at two digits so mod 100:
I am optimistic this idea is original; I have not seen it published. This section will be more rigorous for that reason.
Let's restate what we know using variables. We work in some digit base $ b $. We have a three digit dividend $ u_2 u_1 u_0 $, a two digit divisor $ v_1 v_0 $, and we know their quotient $ q = \lfloor \frac {u_2 u_1 u_0} {v_1 v_0} \rfloor \lt b$ , i.e. fits in a single digit. We compute an estimate $ \hat{q} = \lfloor \tfrac {u_2 u_1 0} {v_1 0} \rfloor $, and the corresponding remainder $ \hat{r} $. We know that $\hat{q}$ is too big iff $ \hat{q} \times v_0 \gt u_0 + \hat{r} $. If so, decrement $ \hat{q} $, recompute $ \hat{r} $, and repeat the check exactly once: if it still too big decrement $ \hat{q} $ once more.
Of course when we decrement the quotient, we may easily compute the new remainder by just adding back the divisor. With this idea we get the following two checks:
If neither are true, then q̂ is precise. If only the first is true, q̂ is too big by 1. If both are true, q̂ is too big by 2.
One non-obvious risk is that the last sum may overflow. This is mitigated by the $ \hat{r} \lt b $ check in both Knuth and Warren. However it is possible to avoid the overflow through some algebra:
How nice is this last expression! $ v_1 v_0 $ is just the original divisor. And the difference $ \hat{q} \times v_0 - (u_0 + \hat{r}) $ may also be used for the first check: if it is not positive, then the inequality in check 1 was not satisifed.
What about overflow? The product $ \hat{q} \times v_0 $ cannot overflow, because $ \hat{q} \le q + 2 \implies \hat{q} \le b + 1 $, therefore $ \hat{q} \times v_0 \le v_0 * b + v_0 $ which clearly does not overflow.
Also the sum $ u_0 + \hat{r} $ does not overflow, because $ \hat{r} \lt v_1 0 $, therefore $ \hat{r} + u_0 \lt v_1 u_0 $.
This idea more efficiently finds $ q $ in the 3 ÷ 2 case, avoiding the loop and some other checks from Knuth. See the next post for an updated narrowing division algorithm that exploits this idea.
letmutiter=0..n;foriiniter{ifi>2{break;}}// silent copy of iteriter.collect()
so Ranges which are not used as iterators (many cannot be, like Range<f64> or Range<char>) pay the price, and so does any type which embeds a Range.
This is abusing the borrow checker as a bad linter. Range undermines the story of lifetimes and ownership, making the borrow checker feel arbitrary.
Range is unsure when it is valid
Rust will happily construct a backwards Range, which ends before it starts:
letx=5..0;x.contains(&4);// false
Is this backwards range valid? Its len() is 0, it contains() nothing, it yields nothing as an iterator. But if you try to use it to index into a slice, you get a panic! So it looks valid but is primed to explode!
This is because - again - you can make a Range of anything. If you try to enforce that start <= end, you lose the ability to make a Range of non-comparable things. A Range of dyn Error can’t be invalid, so a Range of int never gets to be.
A practical problem is writing correct bounds checks. For example, consider the get_unchecked function on slice - it says “an out-of-bounds index is undefined behavior” but never defines what out of bounds means. So how does one even call this function safely?
Restated: a Range with start 0 and length 0 may be out of bounds. That’s wild.
Range hides a footgun
A regex engine (here’s one) often deals in ranges of char, for example /[a-z]/. Should it use Range<char>?
No! The footgun is /[\u10FFFF]/, which is the largest char. Range<char> cannot represent this value, even though it has the bits to do so.
Is RangeInclusive a better choice? This uses an additional bool field to mean…stuff, and it needs to be separately checked in several places. This is a silly expensive representation, pushing RangeInclusive<char> to 12 bytes even though it would fit in 8, with bits to spare. Not a good choice for a perf-sensitive regex algorithm.
A Recipe for Rearranging Range
The problem is Range is overloaded: it’s too flexible, it wants to be everything.
It’s sometimes a set
It’s sometimes an iterator
It’s sometimes a slice index
You can make silly Ranges out of anything
These goals are in tension, and it meets none of them well.
Perhaps it’s too late and we must live with this wart, but a recipe for a different approach:
Limit Range to Copy + PartialOrd types. There may be occasional uses for Range<String> or Range<BigNum>, but it’s not worth forcing borrowing for the common case.
Now that Range always knows how to compare its ends, enforce that start <= end at construction time. For Ranges constructed from constants, this will be free. This avoids the “looks valid, actually explodes” problem and will unlock further optimizations:
Range::is_empty() could be written naturally instead of a a bizarre way just for NaNs
Give Range an iter() method, like other collections have. Now Range is not an Iterator, just like Vec is not an Iterator, and Range can be easily made Copy. This does mean writing for n in (1..10).iter(), but Rust already requires that for collections, so it’s more consistent.
Now that Range is not an Iterator, RangeInclusive can drop its extra bool. It would simply be a pair of indexes, and could not be empty (that’s what Swift does).
JavaScript rounds in a tricky way. It tricked all the engines, and even itself.
Math.round() behaves the same as C’s familiar round with one key difference: it rounds halfways (“is biased”) towards positive infinity. Here is its spec in ES 5.1. It suggests an implementation too:
The value of Math.round(x) is the same as the value of Math.floor(x+0.5)...
However this fails on the other end: when x is large enough that fractional values can no longer be represented, x + 0.5 rounds up to x + 1, so JSRounding a large integer like Math.pow(2, 52) would actually increment it.
What's a correct implementation? SpiderMonkey checks on the high end, and exploits the loss of precision on the low end:
staticconstdoublekIntegerThreshold=1LLU<<52;doublejsround(doublex){doubleabsx=fabs(x);if(absx>kIntegerThreshold){// x is already integralreturnx;}elseif(absx<0.5){// x may suffer precision loss when adding 0.5// round to +/- 0returncopysign(0,x);}else{// normal rounding.// ensure negative values stay negative.returncopysign(floor(x+0.5),x);}}
The ES6 spec sheepishly no longer suggests an implementation, it just disavows one:
Math.round(x) may also differ from the value of Math.floor(x+0.5) because of internal rounding when computing x+0.5...
JavaScript presumably rounds this odd way to match Java, and so the only engine to get it right out of the gate is Rhino, which simply calls back to Java's Math.round. Amusingly Oracle fell into the same trap with Rhino's successor Nashorn. Round and round we go!
At very small scales, particles are described by wavefunctions that obey the Schrödinger Equation. What do wavefunctions look like?
The Wavefiz is a nifty visualizer that draws them! It's real physics: we're solving the Schrödinger Equation in real time with arbitrary potentials. But it's also just plain fun to play with!
There's some non-mathy exercises to do too. Have you heard of the ground state energy or quantum tunnelling? Those pop right out - you can see them visualized.
The visualizer was built using three.js and TypeScript. You can pitch in here on GitHub. And if you like quantum physics, and are near Silicon Valley, come meetup to learn quantum mechanics with us!
The Amazon Dash is a $5 WiFi button that summons a truck to deliver you water or other stuff. Want your Dash to do something else? The popular approach is to sniff its ARP requests. This requires that Dash connect to your network, putting you perilously close to having some DUDE delivered with your IoT mood lighting.
A more immediate problem is immediacy, or lack thereof: the Dash button only connects to your network after being pressed, so there's a ~5 second delay before anything can happen! This makes the ARP Dash hack unsuitable for interactive uses, like doorbells.
Can we make it faster? Here's one way:
"Setup" the Dash with a unique network SSID for a network that doesn't exist
Use a WiFi adapter in monitor mode to observe probe requests on that network SSID
This responds in < 1 second, which is fast enough for real time uses. And you don't even have to give the thing your password.
A Raspberry Pi works when equipped with a WiFi adapter capable of monitoring mode. The RT5370 chipset is so capable - here's the onefish bought. Steer clear of the ubiquitous Realtek RTL8188CUS based devices.
fish 2.0 is now released! fish is a fully-equipped command line shell (like bash or zsh) that is smart and user-friendly. fish supports powerful features like syntax highlighting, autosuggestions, and tab completions that just work, with nothing to learn or configure.
This marks the first release of fish in over four years, and includes many new features, fixes, and optimizations. See the release notes for a partial list of what's new.
A big debt of gratitude to everyone who contributed to this release, including:
"Asswipe," replied Yahoo's server. That's when I knew I had it.
Yahoo's public chat rooms have passed away. It is for the best, for the spam had spread everywhere. But they had a good run, operating for a decade and a half, an Internet eternity.
Here are three funny stories from the Yahoo chat protocol.
Body and Zoul
Yahoo chat rooms started life as a Java applet, chugging along in Netscape Navigator 4. Support for chat was later added to Pager, their native app, which did its own chugging in Visual Basic. Initially, Pager had custom text rendering, but then they replaced it with an HTML view.
Oops. Pager didn't escape message contents, and so it was possible for a message sender to coax the recipient into displaying arbitrary HTML - even fetching images off the web. XSS in its infancy.
Oh dear, what to do? Not everyone would install a security update. But all messages went through Yahoo's servers, so they could fix it server-side: block the attack by rewriting the messages before sending them along. So Yahoo replaced the troublesome opening bracket < with a letter that sort of looked like a bracket: a capital Z. Messages containing <html> or <body> would be rewritten to Zhtml> and Zbody>.
And more than a decade later, this methuselan workaround lives on:
md55555555555...
Yahoo chat was not as full of sexually unfulfilled college girls as the spam bots would have you believe. Before the captchas arrived in 2007 (which did little in any case), Yahoo battled the bots by obfuscating the login protocol. And once the bots caught up, obfuscating it again. Rinse and repeat - by the end, the protocol had grown to outrageous complexity. A puny excerpt of the login sequence:
md5 the user's password
md5 the password, followed by the fixed salt, followed by the password again
md5 the password, followed by a fixed salt, followed by the second hash, followed by parts of the password, but interspersed with zeros
hash the password
hash the third hash
Iterate the previous two steps 50 times, including the password in the hash every seventh time, and salting the hash too, except every third time
md5 the result of that loop...
And we have only barely begun. Should you wish to dive further, see the function yahoo_process_auth_0x0b.
The Sacred, but Mostly the Profane
fish wrote a client for Yahoo chat, but the protocol was not public. Reverse engineering the login protocol for a native OS X client meant running Ethereal in X11 to inspect a Java program running in the OS 9 Classic environment: a remarkable feat, but man, was it slow going. For a long time, connection attempts were met with radio silence and disconnection. Nothing, nothing, nothing...
And then, all at once, Yahoo unleashed a stream of filthy, filthy obscenities. Yessss.
You see, Yahoo was concerned that people might swear on the Internet, so they provided a list of words that the client should filter. But this list might need to be updated dynamically, in case someone on the Internet managed to think up a new word for sex. So rather than build the list into the client, they sent it to you from the server. Right in the first packet. In alphabetical order. Login successful, bitch.
This post was written sixteen months ago, when fish briefly explored Go with the intention of writing a new command line shell. (fish abandoned Go after discovering that terminal programming is what makes shells so horrible, and term programming is least horrible in C.)
These are some notes fish took as he explored Go, and as a result they're mostly unstructured, unbalanced, and surface-level. There's likely errors, dumb omissions, and simple misunderstandings on his part. Still it's nevertheless interesting to see what's changed in those sixteen months. Original text is in black, new text is in red.
I used Google's new Go language for two days. This qualifies me to bloviate on it, so here goes.
The language (unsurprisingly) feels like a modernized C, with design decisions that reflect an apparent consensus on best practices. The language is strictly typed, but supports some limited type inference, to save on keypresses (what the designers call "stuttering"). There's no more header files. It's garbage collected and supports closures. There's pointers, but no pointer arithmetic. There's multiple return values. Strings are built-in and immutable. It feels modern!
But it is C-like, in that it omits a lot of the heavyweight bondage and discipline found in other languages. Data aggregation is done through structs, and there's no access controls: all fields are public. There's no subtyping - in fact, there's no type hierarchy at all. There's no generics, no exceptions, no operator overloading, nada.
In C you spend less time building up a super-structure of type relationships, const-correctness, and abstraction, and more time working on the actual problem. Go seems to be designed in the same spirit of simplicity and transparency. Where so many other modern languages focus on this superstucture, it is refreshing to see a modernized language in the spirit of C.
Syntax
Much has been made of Go's syntax, which at first blush seems pointlessly inverted from C. For example, variable and function return types go after the identifier. But I found the syntax to be simpler and more regular than C: there's fewer extraneous elements, like required parenthesis and useless voids. For example, this Go function I wrote:
However in other ways, brevity suffers. Branching is one of the most serious victims: with no ternary operator, and with the requirement that 'if' uses open braces with a particular style, the best you can do is this:
if expr {
n = trueVal
} else {
n = falseVal
}
This remains true.
Another syntax / semantics oddity is the behavior of reading from channels (like a pipe). Whether a read from a channel blocks depends on how the return value is used:
res := <- queue /* waits if the queue is empty */
res, ok := <- queue /* returns immediately if the queue is empty */
This bears repeating: the behavior of a channel read depends on how the return value is (will be) used. This seems like a violation of the laws of time and space!
By the way, the :=<- idiom is called the Overbite Man.
Semicolons
An aside on semicolons: Go programs don't terminate statements with semicolons. Wait, let me rephrase: Go allows you to insert the semicolons, but doesn't require them. Losing semicolons is nice, but the simplicity is only apparent, because to be proficient in Go you still must understand the rules governing Go semicolons.
This is because, instead of omitting semicolons from the grammar, they are injected automatically by the lexer. This isn't an academic distinction, because the abstraction is leaky. For example, here's an error I got from the cgo tool:
test.go:75:1: expected ';', found 'EOF'
The error message's advice is incorrect. The true problem is that the file didn't end with a newline.
That Damnable Use Requirement
Go will refuse to compile a file that has an unused variable or package import. This sounds hygenic, like it's a way to prevent the inevitable accumulation of unused header imports that torment C projects. But in practice, this is a dreadful, dreadful feature. Imagine this:
Something doesn't work right, so you add a call to fmt.Printf to help debug it.
Compile error: "Undefined: fmt."
You add an import "fmt" at the top.
It works, and you debug the problem.
Remove the now annoying log.
Compile error: "imported and not used: fmt."
Remove the "fmt" knowing full well you're just going to be adding it back again in a few minutes.
Repeat a dozen times a day, and it's a recipe for hair-pulling.
Furthermore, some developers compile every few lines, as a sort of sanity check. This is not possible in Go: inevitably you will introduce a variable that you just haven't used yet, and the compile will error out.
This one irritant is the most annoying part of writing in Go.
The damnable use requirement lives on to this day. This requirement would be right at home in a bondage and discipline language, which may explain why it feels so out of place in Go.
C Compatibility
Here's a brighter spot. Go has a foreign function interface to C, but it receives only a cursory note on the home page. This is unfortunate, because the FFI works pretty darn well. You pass a C header to the "cgo" tool, and it generates Go code (types, functions, etc.) that reflects the C code (but only the code that's actually referenced). C constants get reflected into Go constants, and the generated Go functions are stubby and just call into the C functions.
The cgo tool failed to parse my system's ncurses headers, but it worked quite well for a different C library I tried, successfully exposing enums, variables, and functions. Impressive stuff.
Where it falls down is function pointers: it is difficult to use a C library that expects you to pass it a function pointer. I struggled with this for an entire afternoon before giving up. Ostsol got it to work through, by his own description, three levels of indirection.
The cgo documentation has since been vastly improved and is given higher billing on the home page. While I don't think it's quite up to the task of handling term programming, it remains a fabulous feature.
Another welcome change is that Go seems to have hidden some of its Plan 9 naming conventions. For example, at the time of the original post, the Go compiler was '6g'; now it is just 'go'.
Unicode
Go looooves UTF-8. It's thrilling that Go takes Unicode seriously at all in a language landscape where Unicode support ranges from tacked-on to entirely absent. Strings are all UTF-8 (unsurprisingly, given the identity of the designers). Source code files themselves are UTF-8. Moreover, the API exposes operations like type conversion in terms of large-granularity strings, as opposed to something like C or Haskell where case conversion is built atop a function that converts individual characters. Also, there is explicit support for 32 bit Unicode code points ("runes"), and converting between runes, UTF-8, and UTF16. There's a lot to like about the promise of the language with respect to Unicode.
But it's not all good. There is no case-insensitive compare (presumably, developers are expected to convert case and then compare, which is different).
Since this was written, Go added an EqualFold function, which reports whether strings are equal under Unicode case-folding. This seems like a bizarre addition: Unicode-naïve developers looking for a case insensitive compare are unlikely to recognize EqualFold, while Unicode-savvy developers may wonder which of the many folding algorithms you actually get. It is also unsuitable for folding tasks like a case-insensitive sort or hash table.
Furthermore, EqualFold doesn't implement a full Unicode case insensitive compare. You can run the following code at golang.org; it ought to output true, but instead outputs false.
Operations like substring searching return indexes instead of ranges, which makes it difficult to handle canonically equivalent character sequences. Likewise, string comparison is based on literal byte comparisons: there is no obvious way to handle the precomposed "San José" as the same string as the decomposed "San José". These are distressing omissions.
To give a concrete example, do a case-insensitive search for "Berliner Weisse" on this page in a modern Unicode-savvy browser (sorry Firefox users), and it will correctly find the alternate spelling "Berliner Weiße", a string with a different number of characters. The Go strings package could not support this.
My enthusiasm for its Unicode support was further dampened when I exercised some of the operations it does support. For example, it doesn't properly handle the case conversions of Greek sigma (as in the name "Odysseus") or German eszett:
This outputs "ὀδυσσεύσ" and "WEIßE ELSTER", instead of the correct "ὀδυσσεύς" and "WEISSE ELSTER."
In fact, reading the source code it's clear that string case conversions are currently implemented in terms of individual character case conversion. For the same reason, title case is broken even for Roman characters: strings.ToTitle("ridiculous fish") results in "RIDICULOUS FISH" instead of the correct "Ridiculous Fish." D'oh.
Go has addressed this by documenting this weirdo existing behavior and then adding a Title function that does proper title case mapping. So Title does title case mapping on a string, while ToTitle does title case mapping on individual characters. Pretty confusing.
Unicode in Go might be summed up as good types underlying a bad API. This sounds like a reparable problem: start with a minimal incomplete string package, and fix it later. But we know from Python the confusion that results from that approach. It would be better to have a complete Unicode-savvy interface from the start, even if its implementation lags somewhat.
...our experience has been that programmers use them as a crutch to avoid thinking about proper error handling and reporting. Proper error handling means that servers continue operation after non-fatal errors instead of crashing. Proper error reporting means that errors are direct and to the point, saving the programmer from interpreting a large crash trace. Precise errors are particularly important when the programmer seeing the errors is not familiar with the code...Time invested writing a good error message now pays off later when the test breaks.
This is the "moon rover" philosophy: if something unexpected happens to the moon rover, it should relay as much information as it can, and keep going no matter the cost. This is a defensible position. I would expect to see some sort of error handling infrastructure, and precise error reporting. But there's not:
If you index beyond the bounds of an array, the error is "index out of range." It does not report what the index is, or what the valid range is.
If you dereference nil, the error is "invalid memory address or nil pointer dereference" (which is it, and why doesn't it know?)
If your code has so much as a single unused variable or import, the compiler will not "continue operation," and instead refuse to compile it entirely.
Some of what I wrote above seems a little snarky / petty, but there it is. Regardless, Go still chooses to not support assertions.
Compile times
Go's compilation speed receives top billing on the home page, with the claim "typical builds take a fraction of a second." At first blush it seems to be so. The single-file project I spent a day on compiles in two hundreths of a second. The 45 file math package compiles in just under a second. Wow!
The compile speed claims seems to have since been removed, so I also removed some ill-conceived ramblings. Here's a summary of what I found 16 months ago:
For small compiles, the Go compiler was blazingly fast; on a large synthetic codebase (700 files), it was three times slower than clang compiling C.
The Go compiler does not support incremental or parallel compilation (yet). Changing one file requires recompiling them all, one by one.
You could theoretically componentize an app into separate packages. However it appears that packages cannot have circular dependencies, so packages are more like libraries than classes.
I don't know to what extent these findings still apply, if at all. Building on the latest release errored with a cryptic "nosplit stack overflow" message, which I did not dig into.
Concurrency
The most important and unusual feature of Go is its concurrency mechanism. To summarize, the "go" keyword can be applied in front of a function call, which will be executed in the background, concurrent with the remainder of the function and all other so-called "goroutines." Goroutines are lightweight. Communication between goroutines is via "channels," which are thread safe queues. A channel is parametrized by some type: you can make a channel of ints, of strings, of structs, etc. This is an attractive mechanism, especially compared to traditional pthreads.
At this point the notes become sparse; the remainder of the text is new content presented in black so as not to exhaust your retinas.
Goroutines
A goroutine is a thread which is scheduled in user-space, and so less expensive than kernel threads. Overhead is a few KB. The docs say, "It is practical to create hundreds of thousands of goroutines in the same address space." Cool!
You can create a goroutine with any function, even a closure. But be careful: a questionable design decision was to make closures capture variables by reference instead of by value. To use an example from Go's FAQ, this innocent looking code actually contains a serious race:
values := []string{"a", "b", "c"}
for _, v := range values {
go func() {
fmt.Println(v)
done <- true
}()
}
The for loop and goroutines share memory for the variable v, so the loop's modifications to the variable are seen within the closure. For a language that exhorts us to "do not communicate by sharing memory," it sure makes it easy to accidentally share memory! (This is one reason why the default behavior of Apple's blocks extension is to capture by value.)
fish Fails at Making a Thread Safe Set
To explore Go's concurrency, I attempted to make a thread-safe set. The set "runs" in its own goroutine, which not only enables thread safety, but also allows clients to insert data into the set and move on, while the set rehashes in the background - something that a lock-based implementation cannot do!
Let's make a type for the set, SafeSet:
type SafeSet struct {
set map[string] bool
adder chan string
}
There's a map that will be protected by a goroutine, and a channel. The goroutine reads values from the channel, and adds them to the map.
The set needs a way to test for membership. I took a design cue from the old Go tutorial, which implements an object's methods by having a separate channel for each request "type," so we add a "test" channel. The test channel must receive the value to test, and also a channel to send the result. So we package up the value to be looked up and the result channel into a little struct. We send this on the "test' channel:
type SetTest struct {
val string
result chan bool
}
type SafeSet struct {
set map[string] bool
adder chan string
tester chan SetTest
}
Little single-use types like SetTest seems to be a common idiom in Go. Next, we can introduce a function that services a SafeSet, and all of its channels:
func (set *SafeSet) run() {
for {
select {
case toadd := <- set.adder:
set.set[toadd] = true
case testreq := <- set.tester:
testreq.result <- set.set[testreq.val]
}
}
}
Lastly we make a function that creates a SafeSet, by allocating all of its components and kicking off the goroutine:
That magic number "16" is the buffer size of the channel: it can hold 16 values in-flight. (A channel can also be unbuffered, which causes a reader to block until a writer is available, and vice-versa.)
The channels are buffered so the client can insert into the set and then move on, even if the set is busy. Not shown is deletion, or wrapper functions; the entire code is here.
As far as I can tell, this is idiomatic Go (or at least it was 16 months ago). Much of the code is concerned with packaging requests and then demultiplexing them in the goroutine. This seems like needless boilerplate: why not instead simply pass a closure over a channel that the goroutine will execute? I have never seen this technique used in Go, but it seems natural to me. (It's essentially how libdispatch works.)
In the ObjC SafeSet, the role of the goroutine is played by the dispatch queue, which is passed closures that it executes. "Ravioli types" like SetTest are obviated by the closures, which automatically package referenced values up into blocks. And there's a convenient facility ('dispatch_sync') to execute a block synchronously, which in Go you must simulate by reading from a channel.
On the other hand, Go's channel mechanism gives you close control over buffer sizes, allowing you to implement rate-limiting of client callers. Channels also provide a natural replacement for callbacks. For example, in Go, you can ask to receive OS signals by simply providing a channel of ints, and then reading from the channel however you like. Dispatch has no such natural mechanism: instead you must specify both a handling block and the queue on which it should be executed.
So some tasks are simpler in Go, and others are simpler in libdispatch. There is no need to pick a winner. Both concurrency mechanisms are a huge improvement over traditional techniques like pthreads.
Deadlocks
Our SafeSet has a function that checks whether a value is in the set. Perhaps we want to add a new function that takes an array and returns whether any of its members are in the set. Recall that, in order to check if a value is in a set, we allocate a channel and pass it to the set; it returns the boolean answer on the channel. As an optimization, I allocated one channel and used it for all the values:
func (set *SafeSet) get_any(strs []string) bool {
result := false
recv_chan := make(chan bool)
for _, s := range strs {
request := SetTest{s, recv_chan}
set.tester <- request
}
for i := 0; i < len(strs); i++ {
result = result || <- recv_chan
}
return result
}
This works for the first call, but it fails for subsequent calls. The problem is that get_any does not read out all of the values from the channel, so the SafeSet gets stuck writing to them. We could fix it in a few ways; one is to make the channel big enough to hold all values:
func (set *SafeSet) get_any(strs []string) bool {
result := false
recv_chan := make(chan bool, len(strs))
for _, s := range strs {
request := SetTest{s, recv_chan}
set.tester <- request
}
for i := 0; i < len(strs); i++ {
result = result || <- recv_chan
}
return result
}
Better, because the SafeSet now has enough space to write all of the output values. But are we guaranteed enough space to write all of the input values? Might the set.tester <- request line block?
It might. Or maybe we get lucky, depending on the buffer size that we give the input channel. Up above, we chose a buffer size of 16, without any real justification for that number, but now we see that it has a deep significance. We can pass get_any an array of size 16 or less, and it will work; if we were incautious, we may not discover that larger arrays fail in testing.
Or maybe we do discover it, but what we don't realize is that the size of 16 is a global resource. Imagine if two goroutines both attempt to call test_any with an array of length 10: it may be that both manage to get 8 of their values on the input channel, and then deadlock.
It's worth pointing out that Go detects and reports deadlocks that involve all goroutines. However, if any goroutine in the process is able to run, the deadlock is unreported. So while this deadlock detection is a cool feature, it can be defeated by a simple infinite loop. In a real program, with multiple independent goroutines, the deadlock reporting is unlikely to be useful.
Races
But there's a far more serious bug: a client that inserts into SafeSet may not see that value appear in the set immediately. The client enqueues on the adder channel, and then the tester channel, but there's no guarantee that the SafeSet will handle the requests in that order. Using multiple channels was an irreparable mistake on my part.
SafeSet Conclusions
My attempt as a newbie to write a SafeSet was discouraging, because I introduced lots of bugs that naive testing missed:
add followed by get may falsely return that the value is not in the set.
get_any worked the first call, but not subsequent calls.
get_any failed for arrays larger than size 16.
get_any might fail on any size for concurrent access.
These bugs occurred only because I chose to make the channels buffered. If all channels were unbuffered, none of these problems could occur (but there would be more limited parallelism).
Mark Summerfield's Attempt
Mark Summerfield, in his book Programming in Go, also implemented a similar object, which he coincidentally called a SafeMap. Summerfield avoided all of these bugs by multiplexing up all different commands onto a single channel. This means he needs a way to distinguish between commands, and here it is:
The commands are wrapped up in functions like these:
func (sm safeMap) Len() int {
reply := make(chan interface{})
sm <- commandData{action: length, result: reply} return (<-reply).(int)
}
(Check out that last line.)
Lastly, the commands are demultiplexed in the goroutine in a big switch statement. So each method of SafeMap must be represented three different ways:
A function exposed to clients
A value in an enum (i.e. the Command pattern)
The actual implementation in the goroutine
Summerfield's approach avoided the bugs I introduced, but also requires a lot of boilerplate and does not allow for much parallelism.
Conclusions
On balance, I like Go and I hope it succeeds. My impression is that it's a strong foundation that gets marred in the details by some poor design decisions. Here's what I thought was good, and what was other.
Thumbs Up
Go captures much of the spirit of C, by eschewing the super-structure of type relationships, const-correctness, and "bondage and discipline" common in other modern languages. A modernized C is a compelling and unfilled niche.
Go feels modern in a balanced and familiar way, by incorporating features such as limited type inference, garbage collection, and multiple return values. In many areas Go does not try to introduce anything new, but instead codifies and unifies existing best practices from other languages. It's conservative in its design.
Go's inverted syntax for variable declarations is unusual and unfamiliar at first, but proves quickly to be simpler than and superior to C.
Channels and goroutines combine to make a powerful and flexible concurrency mechanism.
The C foreign function interface "cgo" works quite well.
Despite what they say, the string type is not Unicode savvy, and the Unicode additions to it are sparse and non-conforming.
Closures capture by reference, which makes it easy to introduce subtle, hard to spot bugs that may not be caught by testing.
Mark Summerfield's SafeMap feels like Java, because it requires repeating everything multiple times. It's a distressing example that I hope is not representative of Go.
I found buffered channels hard to reason about, for two, uh, reasons:
A deadlock can be masked in testing by a channel's buffer. Unfortunately there are no channels with a dynamic or growable buffer: you must pick a fixed size at channel creation time.
Threads exchange data only, instead of code and data (like in libdispatch). As a result, it's tempting to send different actions over different channels, as in the original Go tutorial. But this can introduce bugs: the actions can be dequeued and executed in a order different from how they were enqueued.
Good luck to Go, and I look forwards to hearing about all the things I got wrong!
The new fish is a POSIX command line shell with delightful, intuitive features like autosuggestions, 256 color syntax highlighting, web based configuration, and lots more. Best of all, these features just work, out of the box. No arcane syntax, no twiddling obscure knobs.
It runs inside your favorite terminal emulator, such as Terminal.app, xterm, or iTerm. You'll feel right at home with its familiar syntax, and its new features will make you instantly more productive, without getting in your way.
Of course, the new fish also has the advanced features you expect from a shell, like customizable prompts, user-defined functions, scripting, programmable completions (that just work, out of the box), etc. There's also a great community and tons of documentation. It's perfect for anyone who uses the command line, but doesn't want to spend all their time learning its idiosyncrasies.
You'll be so glad you did. Seriously, those autosuggestions have ruined me for all other shells.
The new fish is in open beta, but is plenty stable enough for everyday use: I use it exclusively on all of my systems. There's an OS X installer and a Debian/Ubuntu installer, and a source tarball for other Unix-like OSes. The download page also has contact information for your questions and love letters / hate mail.
I owe a debt of gratitude to Siteshwar Vashisht for his great contributions, and of course the original developer Axel for authoring fish in the first pace.
This is a technique fish thought up for improving the performance of unsigned integer division by certain "uncooperative" constants. It does not seem to appear in the literature, nor is it implemented in gcc, llvm, or icc, so fish is optimistic that it is original.
As is well known (and seen in a previous post), compilers optimize unsigned division by constants into multiplication by a "magic number." But not all constants are created equal, and approximately 30% of divisors require magic numbers that are one bit too large, which necessitates special handling (read: are slower). Of these 30%, slightly less than half (46%) are even, which can be handled at a minimum of increased expense (see below); the remaining odd divisors (659 million, including well known celebrity divisors like 7) need a relatively expensive "fixup" after the multiplication. Or so we used to think. This post gives a variation on the usual algorithm that improves performance for these expensive divisors.
This post presents the algorithm, proves it is correct, proves that it applies in every case we care about, and demonstrates that it is faster. It also contains a reference implementation of the full "magic number" algorithm, incorporating this and all known techniques. In other words, it's so darn big that it requires a table of contents.
Unsigned integer division is one of the slowest operations on a modern microprocessor. When the divisor is known at compile time, optimizing compilers do not emit division instructions, but instead either a bit shift (for a power of 2), or a multiplication by a sort of reciprocal (for non-powers of 2). This second case involves the identity:
$\lfloor \frac n d \rfloor = \lfloor \frac n d \times \frac {2^k} {2^k} \rfloor = \lfloor \frac {2^k} d \times \frac n {2^k} \rfloor$
As d is not a power of 2, $\frac {2^k} d$ is always a fraction. It is rounded up to an integer, which is called a "magic number" because multiplying by it performs division, as if by magic. The rounding-up introduces error into the calculation, but we can reduce that error by increasing k. If k is big enough, the error gets wiped out entirely by the floor, and so we always compute the correct result.
The dividend (numerator) is typically an N bit unsigned integer, where N is the size of a hardware register. For most divisors, k can be small enough that a valid magic number can also fit in N bits or fewer. But for many divisors, there is no such magic number. 7, 14, 19, 31, 42...these divisors require an N+1 bit magic number, which introduces inefficiences, as the magic number cannot fit in a hardware register.
Let us call such divisors "uncooperative." The algorithm presented here improves the performance of dividing by these uncooperative divisors by finding a new magic number which is no more than N bits. The existing algorithm that generates an N+1 bit magic number for uncooperative divisors will be referred to as the "round-up algorithm", because it rounds the true magic number up. The version presented here will be called the "round-down algorithm". We will say that an algorithm "fails" or "succeeds" according to whether it produces a magic number of N bits or fewer; we will show that either the round-up or round-down algorithm (or both) must succeed for all divisors.
All quantities used in the proofs and discussion are non-negative integers.
A Shift In Time Saves Fourteen
For completeness, it is worth mentioning one additional technique for uncooperative divisors that are even. Consider dividing a 32 bit unsigned integer by 14. The smallest valid magic number for 14 is 33 bits, which is inefficient. However, instead of dividing by 14, we can first divide by 2, and then by 7. While 7 is also uncooperative, the divide by 2 ensures the dividend is only a 31 bit number. Therefore the magic number for the subsequent divide-by-7 only needs to be 32 bits, which can be handled efficiently.
This technique effectively optimizes division by even divisors, and is incorporated in the reference code provided later. Now we present a technique applicable for odd divisors.
First, an appeal to intuition. A divisor is uncooperative in the round-up algorithm because the rounding-up produces a poor approximation. That is, $\frac {2^k} d$ is just slightly larger than some integer, so the approximation $\lceil \frac {2^k} d \rceil$ is off by nearly one, which is a lot. It stands to reason, then, that we could get a better approximation by floor instead of ceil: $m = \lfloor \frac {2^k} d \rfloor$.
A naïve attempt to apply this immediately runs into trouble. Let d be any non-power-of-2 divisor, and consider trying to divide d by itself by multiplying with this magic number:
$ \lfloor \frac {2^k} d \rfloor < \frac {2^k} d \implies $
$ \lfloor \frac {2^k} d \rfloor \times \frac d {2^k} < \frac {2^k} d \times \frac d {2^k} \implies $
$ \lfloor \lfloor \frac {2^k} d \rfloor \times \frac d {2^k} \rfloor < 1 $
The result is too small.
(Could we replace the outer floor by a ceil? The floor is implemented by a right shift, which throws away the bits that are shifted off. We could conjure up a "rounding up" right shift, and that might work, though it would likely be more expensive than the instructions it replaces.)
So rounding down causes us to underestimate the result. What if we tried to counteract that by incrementing the numerator first?
$\lfloor \frac n d \rfloor \ \stackrel{?}{=} \ \lfloor \lfloor \frac {2^k} d \rfloor \times \frac {\color{#FF3030}{n+1}} {2^k} \rfloor $
First we must show that the round-down algorithm actually works. We proceed much like the proof for the round-up algorithm. We have a known constant d and a runtime variable n, both N bit values. We want to find some k that ensures:
$\lfloor \frac n d \rfloor = \lfloor m \times \frac {n+1} {2^k} \rfloor$
where: $$ \small \begin{align} \small & m = \lfloor \frac {2^k} d \rfloor \\
& 0 \le n < 2^{N} \\
& 0 < d < 2^{N} \\
& \text{d not a power of 2} \end{align} $$
Introduce an integer e which represents the error produced by the floor:
$ m = \lfloor \frac {2^k} d \rfloor = \frac {2^k - e} d $
$0 < e < d$
Apply some algebra:
$$\begin{align} \lfloor m \times \frac {n+1} {2^k} \rfloor & = \lfloor \frac {2^k - e} d \times \frac {n + 1} {2^k} \rfloor \\
& = \lfloor \frac {n + 1} d \times \frac {2^k - e} {2^k} \rfloor \\
& = \lfloor \frac {n + 1} d \times ( 1 - \frac e {2^k} ) \rfloor \\
& = \lfloor \frac {n+1} d - \frac {n+1} d \times \frac e {2^k} \rfloor \\
& = \lfloor \frac n d + \frac 1 d - \frac e d \times \frac {n+1} {2^k} \rfloor \end{align} $$
We hope that this equals $\lfloor \frac n d \rfloor$. Within the floor, we see the result, plus two terms of opposite signs. We want the combination of those terms to cancel out to something at least zero, but small enough to be wiped out by the floor. Let us compute the fractional contribution of each term, and show that it is at least zero but less than one.
The fractional contribution of the $\frac n d$ term can be as small as zero and as large as $\frac {d-1} d$. Therefore, in order to keep the whole fractional part at least zero but below one, we require:
$ 0 \le \frac 1 d - \frac e d \times \frac {n+1} {2^k} < \frac 1 d$
The term $\frac e d \times \frac {n+1}{2^k}$ is always positive, so the $< \frac 1 d$ is easily satisfied. It remains to show it is at least zero. Rearranging:
$ 0 \le \frac 1 d - \frac e d \times \frac {n+1} {2^k} \implies \frac e d \times \frac {n+1} {2^k} \le \frac 1 d $
This is very similar to the condition required in the round-up algorithm! Let's continue to simplify, using the fact that n < 2N.
$ \frac e d \times \frac {n+1} {2^k} \le \frac 1 d$
$ e \times \frac {n+1} {2^k} \le 1 $
$ \frac e {2^{k-N}} \le 1 $
$ e \le 2^{k-N} $
This is the condition that guarantees that our magic number m works. In summary, pick some k ≥ N, and compute $ \small e = 2^k \mod{d} $. If the resulting e ≤ 2k-N, the algorithm is guaranteed to produce the correct result for all N-bit dividends.
When will this condition be met? Recall the hand-waving from before: the round-up algorithm failed because rounding up produced a poor approximation, so we would expect rounding down to produce a good approximation, which would make the round-down algorithm succeed. Optimistically, we'd hope that round-down will succeed any time round-up fails! Indeed that is the case, and we can formally prove it now.
Here eup refers to the difference produced by rounding 2k up to a multiple of d, as in the round-up algorithm, while edown refers to the difference produced by rounding down to a multiple of d as in round-down. An immediate consequence is eup + edown = d.
Recall from the round-up algorithm that we try successive values for k, with the smallest k guaranteed to work equal to $ \small N + \lceil log_2 d \rceil $. Unfortunately, this k produces a magic number of N+1 bits, and so too large to fit in a hardware register. Let's consider the k just below it, which produces a magic number of N bits:
$ k = N + \lceil log_2 d \rceil - 1 = N + \lfloor log_2 d \rfloor $
Assume that d is uncooperative, i.e. the magic number for this power was not valid in the round-up algorithm. It would have been valid if $ e_{up} < 2^{\lfloor log_2 d \rfloor} $; because it was not valid we must have $ e_{up} \ge 2^{\lfloor log_2 d \rfloor} $. Substituting in:
$$\begin{align} e_{up} & \ge 2^{\lfloor log_2 d \rfloor} \implies \\
d - e_{down} & \ge 2^{\lfloor log_2 d \rfloor} \implies \\
e_{down} & \le d - 2^{\lfloor log_2 d \rfloor} \implies \\
e_{down} & \le 2^{\lceil log_2 d \rceil} - 2^{\lfloor log_2 d \rfloor} \implies \\
e_{down} & \le 2 \times 2^{\lfloor log_2 d \rfloor} - 2^{\lfloor log_2 d \rfloor} \implies \\
e_{down} & \le 2^{\lfloor log_2 d \rfloor} \implies \\
e_{down} & \le 2^{k-N} \end{align} $$
Thus we've satisfied the condition determined in the proof of correctness. This is an important and remarkable result: the round-down algorithm is guaranteed to have an efficient magic number whenever round-up does not. If the implementation of round-down can be shown to be more efficient, the overflow case for the round-up algorithm can be discarded entirely.
Recap
Here's the practical algorithm. Given a dividend n and a fixed divisor d, where 0 ≤ n < 2N and 0 < d < 2N, and where the usual round-up algorithm failed to find an N-bit magic number:
Consider in turn values of p in the range 0 through $ \small \lfloor log_2 d \rfloor $, inclusive.
If $ \small 2^{N + p}\ \bmod{d} \le 2^p $, then we have found a working p. The last value in the range is guaranteed to work.
Once we have a working p, precompute the magic number $ \small m = \lfloor \frac {2^{N + p}} d \rfloor $, which will be strictly less than 2N.
Compute $ \small q = (m \times (n+1)) \gg N $. This is typically implemented via a "high multiply" instruction.
Perform any remaining shift: $ \small q = q \gg p $.
This algorithm has a wrinkle. Because n is an N-bit number, it may be as large as 2N - 1, in which event the n+1 term will be an N+1 bit number. If the value is simply incremented in an N-bit register, the dividend will wrap to zero, and the quotient will in turn be zero. Here we present two strategies for efficiently handling the possibility of modulo overflow.
Distributed Multiply Strategy
An obvious approach is to distribute the multiply through, i.e.:
$ \small m \times (n+1) = m \times n + m $
This is a 2N-bit quantity and so cannot overflow. For efficient implementation, this requires that the low half of the m x n product be available "for free," so that the sum can be performed and any carry transmitted to the high half. Many modern architectures produce both halves with one instruction, such as Intel x86 (the MUL instruction) or ARM (UMULL). It is also available if the register width is twice the bit size of the type, e.g. performing a 32 bit divide on a 64 bit processor.
Saturating Increment Strategy
However, other processors compute the low and high halves separately, such as PowerPC; in this case computing the lower half of the product would be prohibitively expensive, and so a different strategy is needed. A second, surprising approach is to simply elide the increment if n is already at its maximum value, i.e. replace the increment with a "saturating increment" defined by:
$$ \small
\text{SaturInc}(x) =
\begin{cases}
x+1 & \text{ if } x < 2^N-1 \\
x & \text{ if } x = 2^N-1
\end{cases}
$$
It is not obvious why this should work: we needed the increment in the first place, so how can we just skip it? We must show that replacing increment with SaturInc will compute the correct result for 2N - 1. A proof of that is presented below.
Proof of Correctness when using Saturating Increment
Consider the practical algorithm presented above, with the +1 replaced by saturating increment. If $ \small n < 2^N-1 $, then saturating increment is the same as +1, so the proof from before holds. Therefore assume that $ \small n = 2^N-1 $, so that incrementing n would wrap to 0.
By inspection, $ \small \text{SaturInc}(2^N - 1) = \text{SaturInc}(2^N - 2) $. Because the algorithm has no other dependence on n, replacing the +1 with SaturInc effectively causes the algorithm to compute the quotient $ \lfloor \frac {2^N - 2} d \rfloor $ when n = 2N-1.
Now d either is or is not a factor of 2N-1. Let's start by assuming it is not a factor. It is easy to prove that, if x and y are positive integers and y is not a factor of x, then $ \lfloor \frac x y \rfloor = \lfloor \frac {x-1} y \rfloor $. Therefore it must be true that $ \lfloor \frac {2^N - 1} d \rfloor = \lfloor \frac {2^N - 2} d \rfloor $, so the algorithm computes the correct quotient.
Now let us consider the case where d is a factor of 2N-1. We will prove that d is cooperative, i.e. the round-up algorithm produced an efficient N-bit result for d, and therefore the round-down algorithm is never employed. Because d is a factor of 2N-1, we have $ \small 2^N\ \bmod{d} = 1 $. Consider once again the case of the "last N-bit magic number," i.e.:
$ \small k = N + \lceil log_2 d \rceil - 1 = N + \lfloor log_2 d \rfloor $
Recall that the round-up algorithm computes $ \small e_{up} = d - (2^k\ \bmod{d}) $. This power is acceptable to the round-up algorithm if $ \small e_{up} \leq 2^{k - N} = 2^{\lfloor log_2 d \rfloor} $. Consider:
$$ \begin{align} e_{up} & = d - 2^{\lfloor log_2 d \rfloor} \\
e_{up} & < 2^{\lceil log_2 d \rceil} - 2^{\lfloor log_2 d \rfloor} \\
& < 2 \times 2^{\lfloor log_2 d \rfloor} - 2^{\lfloor log_2 d \rfloor} \\
& < 2^{\lfloor log_2 d \rfloor} \end{align} $$
Thus the power k is acceptable to the round-up algorithm, so d is cooperative and the round-down algorithm is never employed. Thus a saturating increment is acceptable for all uncooperative divisors. Q.E.D.
(As an interesting aside, this last proof demonstrates that all factors of 2N-1 "just barely" have efficient N-bit magic numbers. For example, the divisor 16,711,935 is a factor of 232-1, and its magic number, while N bits, requires a shift of 23, which is large; in fact it is the largest possible shift, as the floor of the base 2 log of that divisor. But increase the divisor by just one (16711936) and only a 16 bit shift is necessary.)
In summary, distributing the multiplication or using a saturating increment are both viable strategies for avoiding wrapping in the n+1 expression, ensuring that the algorithm works over the whole range of dividends. Implementations can use whichever technique is most efficient1.
The discussion so far is only of theoretical interest; it becomes of practical interest if the round-down algorithm can be shown to outperform round-up on uncooperative divisors. This is what will be demonstrated below for x86 processors.
x86 processors admit an efficient saturating increment via the two-instruction sequence add 1; sbb 0; (i.e. "add; subtract 0 with borrow"). They also admit an efficient distributed multiply. The author implemented this optimization in the LLVM compiler using both strategies in turn, and then compiled the following C code which simply divides a value by 7, using clang -O3 -S -arch i386 -fomit-frame-pointer (this last flag for brevity):
unsignedintsevens(unsignedintx){returnx/7;}
Here is a comparison of the generated i386 assembly, with corresponding instructions aligned, and instructions that are unique to one or the other algorithm shown in red. (x86-64 assembly produced essentially the same insights, and so is omitted.)
The round-down algorithms not only avoid the three-instruction overflow handling, but also avoid needing to store the dividend past the multiply (notice the highlighted MOVL instruction in the round-up algorithm). The result is a net saving of two instructions. Also notice that the variants require fewer registers, which suggests there might be even more payoff (i.e. fewer register spills) when the divide is part of a longer code sequence.
(In the distributive variant the compiler has made the dubious choice to emit the same immediate twice instead of placing it in a register. This is especially deleterious in the loop microbenchmark shown below, because loading the immediate into the register could be hoisted out of the loop. To address this, the microbenchmark tests both the assembly as generated by LLVM, and a version tweaked by hand to address this suboptimal codegen.)
As illustrated, both strategies require only two instructions on x86, which is important because the overhead of the round-up algorithm is three to four instructions. Many processor architectures admit a two-instruction saturating increment through the carry flag2.
To measure the performance, the author compiled a family of functions. Each function accepts an array of unsigned ints, divides them by a particular uncooperative divisor, and returns the sum; for example:
A simple test harness was constructed and the above functions were benchmarked to estimate the time per divide. The benchmark was compiled with clang on -O3, and run on a 2.93 GHz Core i7 iMac. Test runs were found to differ by less than .1%.
Nanoseconds Per Divide
Divisor
Round Up
Saturating Increment
Distribute (as generated)
Distribute (hand tweaked)
i386
7
1.632
1.484
9.1%
1.488
8.9%
1.433
12.2%
uint32
37
1.631
1.483
9.1%
1.486
8.9%
1.433
12.1%
123
1.633
1.484
9.1%
1.488
8.9%
1.432
12.3%
763
1.632
1.483
9.1%
1.487
8.9%
1.432
12.2%
1247
1.633
1.484
9.1%
1.491
8.7%
1.433
12.2%
9305
1.631
1.484
9.0%
1.491
8.6%
1.439
11.7%
13307
1.632
1.483
9.1%
1.489
8.7%
1.437
11.9%
52513
1.631
1.483
9.1%
1.490
8.7%
1.432
12.2%
60978747
1.631
1.484
9.0%
1.488
8.8%
1.434
12.1%
106956295
1.631
1.484
9.0%
1.489
8.7%
1.433
12.1%
x86_64
7
1.537
1.307
14.9%
1.548
-0.7%
1.362
11.4%
uint32
37
1.538
1.307
15.0%
1.548
-0.7%
1.362
11.4%
123
1.537
1.319
14.2%
1.547
-0.6%
1.361
11.5%
763
1.536
1.306
15.0%
1.547
-0.8%
1.356
11.7%
1247
1.538
1.322
14.1%
1.549
-0.7%
1.358
11.7%
9305
1.543
1.322
14.3%
1.550
-0.5%
1.361
11.8%
13307
1.545
1.322
14.4%
1.550
-0.3%
1.357
12.1%
52513
1.541
1.307
15.2%
1.550
-0.6%
1.361
11.7%
60978747
1.538
1.322
14.0%
1.549
-0.7%
1.358
11.7%
106956295
1.537
1.322
14.0%
1.551
-0.9%
1.360
11.5%
x86_64
7
1.823
1.588
12.9%
1.505
17.4%
n/a
uint64
39
1.821
1.589
12.7%
1.506
17.3%
n/a
123
1.821
1.592
12.6%
1.506
17.3%
n/a
763
1.822
1.592
12.6%
1.505
17.4%
n/a
1249
1.822
1.589
12.8%
1.506
17.4%
n/a
9311
1.822
1.587
12.9%
1.507
17.3%
n/a
11315
1.822
1.588
12.8%
1.506
17.4%
n/a
52513
1.823
1.591
12.7%
1.506
17.4%
n/a
60978749
1.822
1.590
12.7%
1.507
17.3%
n/a
106956297
1.821
1.588
12.8%
1.506
17.3%
n/a
Microbenchmark results for tested division algorithms on a Core i7. The top group is for 32 bit division in a 32 bit binary, while the bottom two groups are 32 bit and 64 bit division (respectively) in a 64 bit binary.
Times are in nanoseconds per divide (lower is better). Percentages are percent improvement from the Round Up algorithm (higher is better).
These results indicate that the round-down algorithms are indeed faster by 9%-17% (excluding the crummy codegen, which should be fixed in the compiler). The benchmark source code is available at http://ridiculousfish.com/files/division_benchmarks.tar.gz.
A natural question is whether the same optimization could improve signed division; unfortunately it appears that it does not, for two reasons:
The increment of the dividend must become an increase in the magnitude, i.e. increment if n > 0, decrement if n < 0. This introduces an additional expense.
The penalty for an uncooperative divisor is only about half as much in signed division, leaving a smaller window for improvements.
Thus it appears that the round-down algorithm could be made to work in signed division, but will underperform the standard round-up algorithm.
The reference implementation for computing the magic number due to Henry Warren ("Hacker's Delight") is rather dense, and it may not be obvious how to incorporate the improvements presented here. To ease adoption, we present a reference implementation written in C that incorporates all known optimizations, including the round-down algorithm.
The following algorithm is an alternative way to do division by "uncooperative" constants, which may outperform the standard algorithm that produces an N+1 bit magic number. Given a dividend n and a fixed divisor d, where 0 ≤ n < 2N and 0 < d < 2N, and where the standard algorithm failed to find a N-bit magic number:
Consider in turn values of p in the range 0 through $ \small \lfloor log_2 d \rfloor $, inclusive.
If $ \small 2^{N + p}\ \bmod{d} \le 2^p $, then we have found a working p. The last value in the range is guaranteed to work (assuming the standard algorithm fails).
Once we have a working p, precompute the magic number $ \small m = \lfloor \frac {2^{N + p}} d \rfloor $, which will be strictly less than 2N.
To divide n by d, compute the value q through one of the following techniques:
Compute $ \small q = (m \times n + m)) \gg N $, OR
Compute $ \small q = (m \times (n+1)) \gg N $. If n+1 may wrap to zero, it is acceptable to use a saturating increment instead.
Perform any remaining shift: $ \small q = q \gg p $.
On a Core i7 x86 processor, a microbenchmark showed that this variant "round down" algorithm outperformed the standard algorithm in both 32 bit and 64 bit modes by 9% to 17%, and in addition generated shorter code that used fewer registers. Furthermore, the variant algorithm is no more difficult to implement than is the standard algorithm. The author has provided a reference implementation and begun some preliminary work towards integrating this algorithm into LLVM, and hopes other compilers will adopt it.
Footnotes
1. Of course, if n can statically be shown to not equal 2N-1, then the increment can be performed without concern for modulo overflow. This likely occurs frequently due to the special nature of the value 2N-1.
2. Many processor architectures admit a straightforward saturating increment by use of the carry flag. PowerPC at first blush appears to be an exception: it has somewhat unusual carry flag semantics, and the obvious approach requires three instructions:
li r2, 0
addic r3, r3, 1
subfe r3, r2, r3
However PowerPC does admit a non-obvious two-instruction saturating increment. It does not seem to appear in the standard literature, and for that reason it is provided below. Given that the value to be incremented is in r3, execute:
subfic r2, r3, -2
addze r3, r3
The result is in r3. r2 can be replaced by any temporary register; its value can be discarded.
I am at work, heading to a meeting, walking down an empty hallway. As I reach the end, the door opens from the other side, and Steve enters, looking down intently at his iPhone. I step aside so he can pass, but he stops right in the middle of the doorway. He doesn't see me.
I wait. He pokes at his phone. I nervously shuffle my feet. He still is just standing there. Do I dare clear my throat?
Five seconds of eternity go by. At last he looks up and realizes I've been waiting for him. "Hi," he says sheepishly.
This is the true story of the app that was fixed by a crash. We travel back to join fish mid-debugging:
I'm dumbfounded. The thread is just gone. And not just any thread: the main thread.
I don't even know how you make the main thread go away. exit() gets rid of the whole app. Will pthread_exit() do it? Maybe it's some crazy exception thing?
See, I've got a bug report. Surf's Up: Epic Waves doesn't work on this prelease OS. Last year, the game giddily ran through its half-dozen splash screens before landing on its main menu, full of surf boards and power chords. Today, it just sits there silently, showing nothing but black, getting all aggro. The game hasn't changed, but the OS did, and I've got to figure out what's different.
So far this is familiar territory. A black screen could be any old hang. I break out sample, crack open the Surfing carapace, peer inside. It's a big app, with over a dozen threads each doing their separate thing. Nothing unusual at all; in particular nothing that looks like a hang. Except...wait, where's the main thread? It's missing. There is NO MAIN THREAD.
I don't know that the main thread's disappearance is connected to the hang, but it's all I have to go on, so let's investigate.
Does the main thread just dry up and fall off, a sort of programmatic umbilical cord? Maybe this program doesn't need it, instead cobbling together an assortment of other threads into working software.
Or maybe it's violent. Maybe the app is forcibly decapitated but still running, unaware of its state, like some lumbering twelve-legged headless chicken, flapping uselessly, bumping into things.
This is easy to check. I boot it up on last year's OS and take a sample. The main thread is there! So it's decapitation. Now we just have to find the butcher.
My debugging toolbox overfloweth. I start the app in gdb - ah, no, it doesn't like that. Complains and crashes.
No problem. I try dtrace - complains and crashes.
One by one, my tools are blunted against the deceptively upbeat Surf's Up. Maybe it intentionally defeats debugging, maybe it's just some accident of design; either way it's nearly impenetrable. Only sample works. So I take sample after sample, slogging through them, looking for something, anything, to explain the empty black screen, which now seems to be growing, filling my vision...
I head home, frustated.
The next day came with no new ideas, so I decide to consult with my imaginary go-to guy. I close my eyes and picture him: the scruffy beard, the sardonic smirk...
"You're an idiot," says House by way of hello. I think it over, but it doesn't help. I say "The main thread is not calling exit, it's not returning, it's not crashing, so where is it going?"
House says, "You don't know that. That's just what it's telling you. And like I said, you're an idiot, because you believe it. Everybody lies."
"The patient," says House, "starts out fine. And then, from nowhere, WHACK! Off with its head! But the body keeps on going. Pretty cool!"
House continues, "But how is that possible? Most patients don't survive headless. Somehow, this one does, and we need to figure out how. We need to catch it in the act."
"And how would I do that?" I muse.
"Chop off its head."
It's darkly ingenious. I don't have the code for this app, and most of my debugging tools are neutered, but there is one inescapable dependency, one avenue into its underbelly: the OS itself. That's code that I control. I can make the OS treacherous, turn it against the app.
Let's try to crash the main thread and see what happens. I check out the source for a dynamic library the app uses, choose my line, and add a dose of poison:
*(int*)NULL = 0;
I try my weaponized library against a hapless guinea pig, and it dies immediately. So far so good. I set the framework path, and launch Surf's Up...
Power chords! My NULL dereference was medicine, not poison!
I feel my sanity begin to give. "Crashing the app, fixes the app? As if asking for help from an imaginary version of a fake doctor wasn't crazy enough. What does this mean?"
"The head can't fall off," House answers, "if it's already gone."
"You mean, our crash somehow pre-empted a different, bloodier crash? But the app doesn't report any crashes at all."
"Everybody lies," says House.
Hmm. Perhaps the app is surviving through setting a signal handler? It could elide a crash that way, catch it and continue on. If so, then clearing the signal handler should make the app visibly crash, like every other app. I change my weaponized library to clear the signal handler for SIGBUS. Surf's Up launches, then once again hangs at a black screen. No crash.
"It didn't work. I don't think the app is really crashing," I say.
"Everybody lies," repeats House.
I change the code to loop, to reset the handler for ALL signals. I start up the program. Black screen.
"This isn't it," I say. But I'm out of ideas.
"EVERYBODY LIES" insists House.
Desperate, frantic, I change the code to spawn a thread that does nothing except loop, loop, loop, constantly resetting all signal handlers. Then I launch the app. Black screen. Try again. Black. Again. Black. Again.
Crash.
It seems simple in retrospect. Surf's Up went to heroics to swallow signals: its background threads continually set signal handlers that cause only the signalling thread to exit, but leave the remaining threads unharmed. And the app didn't really need its main thread after all.
Except when it did, because when the main thread crashed of its own accord, it did so while holding a lock. And when other threads tried to acquire that lock, they got stuck, because the thread which was supposed to release it was gone. The lock was forever locked! But the problem could be averted by stopping the main thread preemptively. And the simplest way to stop it was to trigger the app's own murderous machinery: dereference NULL.
The crash itself was just a mundane, run-of-the-mill regression, one that was already known and already being investigated. But the signal shenanigans of the app manifested the crash in a totally different way, and its debugging defenses hid its misdeeds. Two minutes thus became two days, but the end result was the same.
Surf's Up was treacherous, smiling as it swallowed bus errors and segmentation faults, as if nothing had gone wrong. fish responded to treachery in kind by temporarily recruiting the OS itself to aid in debugging and ultimately defeat the app's defenses. But these same defenses had a remarkable consequence: attempts to trigger a crash instead precluded a hang. One app's poison is another app's surf boards and power chords.
Maybe you've got a list of things, like friends or appointments or map locations, and you want to give each one its own color so the user can distinguish them easily. The user can make new friends or appointments, so you don't know ahead of time how many colors you'll need. And when the user adds a new item, you want its color to be as different from all other colors as possible, to avoid confusion. How do you decide on the sequence of colors to give each item? And can it be a random-access sequence? It sounds tricky, maybe like some linear optimization problem, but in fact there's a marvelously simple and surprising solution.
We can think of colors in terms of hue, saturation, and lightness. Since these colors are going to be presented next to each other, they have to look good together - no bright colors mixing with dark ones, for example - so the color choices will vary only in hue. That way blues, greens, reds, etc. will all be represented, but they'll all be equally bright and equally saturated.
So let's try to pick some hues on the edge of the color wheel. We want the colors to be maximally different, so each time we add a new hue, we'll try to put it as far away from all the others as we can. The first color can be anything, so let's start with red. The second color then has to go opposite it.
12
The third color needs to be as far away as possible from the first two, which means either the top or bottom. The fourth color then must take bottom or top.
1234
I get it, we just keep on bisecting!
12345678
See a pattern yet? Maybe if we write it out as a list of rotations:
It's easy to continue this series, but it's not obvious how to compute, say, the 100th element. But what if...what if we write it like this (read top to bottom, left to right):
And what if now we just look at the pattern of numerators:
000 100 010 110 001 101 011 111
It's just binary writ backward!
So to compute the Nth color, we want to "mirror image" the bits of N around the decimal point. Another way of doing that is to reverse the bits of N, then shift them right, all the way past the decimal point. Of course bits shifted past the decimal point are normally discarded, but here we can use the opposite of the usual trick and replace a right shift with a divide. Do it in floating point and our bits will get preserved.
Thus, the algorithm to compute the hue of the Nth color in this sequence is:
Reverse the bits of N
Convert to floating point
Divide by 232, assuming N is 32 bit; or use scalbn() if you're fancy
So there is, in fact, a practical use case for reversing the bits of an integer.
You can try it. Click in the area below to add colored circles, and you'll see the quick 'n dirty sequence of colors, starting at 216 degrees. You'll need a CSS3-savvy browser that supports HSL colors. (The JavaScript source is right underneath me!)
If your browser width is such that the number of circles per row is a power of two, you'll see how the distance between colors is strictly one-dimensional.
See how well you know (or can anticipate) gcc's optimizer. For each question, the left box contains some code, while the right box contains code that purports to do the same thing, but that illustrates a particular optimization. Will gcc apply that optimization? Put another way, will the code on the left be as fast as the code on the right, when compiled with an optimizing gcc?
I used a pretty ancient gcc 4.2.1 for these tests. If newer versions have different behavior, please leave a comment.
Beware: not all proposed optimizations are actually valid!
It is tempting to think of compiler optimizations as reducing the constant in your program's big-O complexity, and nothing else. They aren't supposed to be able to make your program asymptotically faster, or affect its output.
However, as we saw, they really can reduce the asymptotic complexity in space (question 1) and time (question 2). They can also affect calculated results (discussion of question 4) and maybe even whether your program goes into an infinite loop (see here).
On the flip side, several "obvious" optimizations are subtly incorrect and so will not be performed by the compiler, especially when they involve floating point. If your floating point code is demonstrably a bottleneck and you don't need exact precision or care about special FP values, you may be able to realize a speedup by doing some optimizations manually. However, untying the compiler's hands through options like -ffast-math is probably a better idea, and then only for the affected files, since these flags have a global impact.
And lastly, this isn't meant to be a prescriptive post, but we all know why micro-optimizing is usually a mistake: it wastes your time, it's easy to screw up (see question 5), and it typically produces no measurable speedup.
Instead of division, there's multiplication by a bizarre number: 1321528399. What wickedness is this?
1321528399 is an example of a "magic number:" a number that lets you substitute speedy multiplication for pokey division, as if by magic. In this post, I become a big fat spoilsport and ruin the trick for everyone.
Dividing by 13 is different than multiplying by 1321528399, so there must be more here than meets the eye. Compiling it as PowerPC reveals a bit more:
_divide:
lis r0,0x4ec4
ori r0,r0,60495
mulhwu r3,r3,r0
srwi r3,r3,2
blr
mulhwu means "multiply high word unsigned." It multiplies by 1321528399, but takes the high 32 bits of the 64 bit result, not the low 32 bits like we are used to. x86-64 does the same thing (notice the shift right instruction operates on %edx, which contains the high bits, not %eax which is the low bits). After multiplying, it shifts the result right by two. In C:
So dividing by 13 is the same as multiplying by 1321528399 and then dividing by 234. That means that 234 divided by 13 would be 1321528399, right? In fact, it's 1321528398.769 and change. Pretty close, but we're not optimizing horseshoes, so how can we be sure this works all the time?
The answer to the question right above this line
It's provable, and hopefully we can get some intuition about the whole thing. In the following proof, division is exact, not that integer-truncating stuff that C does; to round down I'll use floor. Also, this only covers unsigned division: every number that appears is non-negative. (Signed division is broadly similar, though does differ in some details.) Lastly, we're going to assume that the denominator d is not a power of 2, which is weirdly important. If d were a power of 2, we'd skip the multiplication and just use shifts, so we haven't lost any generality.
We have some fixed positive denominator d and some variable nonegative numerator n, and we want to compute the quotient $\frac n d$ - no, wait, $\lfloor \frac n d \rfloor$, since that's what C does. We'll multiply the top and bottom by 2k, where k is some positive integer power - it represents the precision in a sense, and we'll pick its value later:
$\lfloor \frac n d \rfloor = \lfloor \frac n d \times \frac {2^k} {2^k} \rfloor = \lfloor \frac {2^k} d \times \frac n {2^k} \rfloor$
We're going to call that $\frac {2^k} d$ term mexact, because it's our "magic number" that lets us compute division through multiplication. So we have:
$m_{exact} = \frac {2^k} d $
$ \lfloor \frac n d \rfloor = \lfloor m_{exact} \times \frac n {2^k} \rfloor$
This equality looks promising, because we've hammered our expression into the shape we want; but we haven't really done anything yet. The problem is that mexact is a fraction, which is hard for computers to multiply. (We know it's a fraction because d is not a power of 2). The tricky part is finding an integer approximation of mexact that gives us the same result for any dividend up to the largest possible one (UINT_MAX in our case). Call this approximation m. So we have $m \approx m_{exact} $, where m is an integer.
When it comes to approximation, closer is better, so let's start by just rounding m down: $m = \lfloor m_{exact} \rfloor$. Since mexact cannot be an integer, m must be strictly less than mexact. Does this m work, which is to say, does it behave the same as mexact over the range we care about?
We'll try it when the numerator equals the denominator: n = d. Of course then the quotient is supposed to be 1. This leads to:
$\frac d d = m_{exact} \times \frac d {2^k}$
$\implies \frac d d > m \times \frac d {2^k}$
$\implies 1 > \lfloor m \times \frac d {2^k} \rfloor$
That's bad, because that last expression is supposed to be 1. The approximation $m = \lfloor m_{exact} \rfloor$ is too small, no matter what k is.
Ok, let's round up instead: $m = \lceil m_{exact} \rceil = \lceil \frac {2^k} d \rceil$. Does this value for m work?
Now, $\lceil \frac {2^k} d \rceil$ just means dividing 2k by d and then rounding up. That's the same as rounding up 2k to the next multiple of d first, and then dividing exactly by d. (We know that 2k is not itself a multiple of d because d is not a power of 2!) So we can write:
where e is the "thing to add to get to the next multiple of d," which means that 0 < e < d. (Formally, e = d - 2k mod d.) This value e is sort of a measure of how much "damage" the ceil does - that is, how bad the approximation m is.
So let's plug this new m into our division expression, and then apply some algebra:
$\lfloor m \times \frac n {2^k} \rfloor = \lfloor \frac {2^k + e} d \times \frac n {2^k} \rfloor = \lfloor \frac n d + \frac e d \times \frac n {2^k} \rfloor $
This last expression is really cool, because it shows the wholesome result we're after, $\lfloor \frac n d \rfloor$, and also an insidious "error term:" that $\frac e d \times \frac n {2^k}$, which represents how much our ceil is causing us to overestimate. It also shows that we can make the error term smaller by cranking up k: that's the sense in which k is a precision.
K's Choice
We could pick some huge precision k, get a very precise result, and be done. But we defined m to be $\lceil \frac {2^k} d \rceil$, so if k is too big, then m will be too big to fit in a machine register and we can't efficiently multiply by it. So instead let's pick the smallest k that's precise enough, and hope that fits into a register. Since there are several variables involved, our strategy will be to find upper bounds for them, replace the variables with their upper bounds, and simplify the expression until we can solve for k.
So we want the smallest k so that $\lfloor \frac n d \rfloor = \lfloor \frac n d + \frac e d \times \frac n {2^k} \rfloor $. This will be true if the error term $\frac e d \times \frac n {2^k}$ is less than 1, because then the floor operation will wipe it out, right? Oops, not quite, because there's also a fractional contribution from $\frac n d$. We need to be sure that the error term, plus the fractional contribution of $\frac n d$, is less than 1 for that equality to be true.
We'll start by putting an upper bound on the fractional contribution. How big can it be? If you divide any integer by d, the fractional part of the result is no more than $\frac {d - 1} d$. Therefore the fractional contribution of $\frac n d$ is at most $\frac {d - 1} d$, and so if our error term is less than $\frac 1 d$, it will be erased by the floor and our equality will be true.
So k will be big enough when $\frac e d \times \frac n {2^k} < \frac 1 d$.
Next we'll tackle $\frac e d$. We know from up above that e is at most d-1, so we have $\frac e d < 1$. So we can ignore that factor: $\frac n {2^k} < \frac 1 d \implies \frac e d \times \frac n {2^k} < \frac 1 d$.
The term $\frac n {2^k}$ has a dependence on n, the numerator. How big can the numerator be? Let's say we're dividing 32 bit unsigned integers: n ≤ 232. (The result is easily extended to other widths). We can make $\frac n {2^k}$ less than 1 by picking k = 32. To make it even smaller, less than $\frac 1 d$, we must increase k by $\log_2 d$. That is,
$k > 32 + \log_2 d \implies \frac n {2^k} < \frac 1 d$
Since we want k to be an integer, we have to round this up: $k = 32 + \lceil \log_2 d \rceil$. We know that value for k works.
What does that precision do to m, our magic number? Maybe this k makes m too big to fit into a 32 bit register! We defined $m = \lceil \frac {2^k} d \rceil$; plugging in k we have $m = \lceil \frac {2^{32 + \lceil log_2 d \rceil} } d \rceil $.
This is a gross expression, but we can put an upper bound on it. Note that $d < {2 ^ { \lceil log_2 d \rceil } }$, so we can write the following:
$m <= \lceil \frac {2^{32 + \lceil log_2 d \rceil} } {2 ^ { \lfloor log_2 d \rfloor } } \rceil = \lceil {2^{32 + \lceil log_2 d \rceil - \lfloor log_2 d \rfloor} } \rceil $
$ = \lceil {2 ^ { 32 + 1}} \rceil = 2^{33}$
Nuts! Our approximation m just barely does not fit into a 32 bit word!
Since we rounded some stuff, you might think that we were too lazy and a more careful analysis would produce a tighter upper bound. But in fact our upper bound is exact: the magic number for an N-bit division really may need to be as large as N+1 bits. The good news is, there may be smaller numbers that fit in N bits for specific divisors. More on that later!
We are fruitful and multiply
In any case, we now have our magic number m. To perform the division, we need to compute $ \lfloor \frac {m n} {2^k} \rfloor$ as efficiently as possible. m is a 33 bit number, so how can a 32 bit processor efficiently multiply by that? One way would be to use a bignum library, but that would be too slow. A better approach is to multiply by the low 32 bits, and handle the 33rd bit specially, like this:
$$\begin{align} m n & = (m - 2^{32} + 2^{32})n \\
& = (m - 2^{32})n + 2^{32} n \end{align}$$
This looks very promising: m - 232 is definitely a 32 bit number. Furthermore, we can compute that 232n term very easily: we don't even need to shift, just add n to the high word of the product. Unfortunately, it's not right: a 32 bit number times a 33 bit number is 65 bits, so the addition overflows.
But we can prevent the overflow by distributing one of the 2s in the denominator, through the following trick:
$$ \begin{align} \lfloor \frac {n + q} {2^k} \rfloor & = \lfloor \frac {n - q + 2q} {2^k} \rfloor \\
& = \lfloor ( \frac {n - q + 2q} 2 ) / {2^{k-1}} \rfloor \\
& = \lfloor ( \lfloor \frac {n - q} 2 \rfloor + q ) / {2^{k-1}} \rfloor \end{align} $$
Here q is the magic number (minus that 33rd bit) times n, and n is just n, the numerator. (Everything should be multiplied by 232, but that's sort of implicit in the fact that we are working in the register containing the high product, so we can ignore it.)
Can the subtraction n - q underflow? No, because q is just n times the 32 bit magic number, and then divided by 232. The magic number (now bereft of its 33rd bit) is less than 232, so we have q < n, so n - q cannot underflow.
What about that +q? Can that overflow? No, because we can just throw out the floor to get an upper bound of $\frac {n + q} 2$ which is a 32 bit number.
So we have a practical algorithm. Given a dividend n and a fixed divisor d, where 0 < d < 232 and 0 ≤ n < 232:
Precompute $p = \lceil log_2 d \rceil$
Precompute $m = \lceil \frac {2^{32 + p}} d \rceil$. This will be a 33 bit number, so keep only the low 32 bits.
Compute $q = (m \times n) \gg 32$. Most processors can do this with one "high multiply" instruction.
Compute $t = ((n - q) \gg 1) + q$, which is an overflow-safe way of computing (n + q) ≫ 1. This extra addition corrects for dropping the 33rd bit of m.
Perform the remaining shift p: $t = t ≫ (p-1)$
That's it! We know how to efficiently replace division with multiplication. We can see all these steps in action. Here is the assembly that Clang generates for division by 7, along with my commentary:
_divide_by_7:
movl $613566757, %ecx 613566757 is the low 32 bits of (2**35)/7, rounded up
movl %edi, %eax
mull %ecx Multiply the dividend by the magic number
subl %edx, %edi The dividend minus the high 32 bits of the product in %edx (%eax has the low)
shrl %edi Initial shift by 1 to prevent overflow
addl %edx, %edi Add in the high 32 bits again, correcting for the 33rd bit of the magic number
movl %edi, %eax Move the result into the return register
shrl $2, %eax Final shift right of floor(log_2(7))
ret
Improving the algorithm for particular divisors
This algorithm is the best we can do for the general case, but we may be able to improve on this for certain divisors. The key is that e term: the value we add to get to the next multiple of d. We reasoned that e was less than d, so we used $\frac e d < 1$ as an upper bound for e. But it may happen that a multiple of d is only slightly larger than a power of 2. In that case, e will be small, and if we're lucky, it will be small enough to push the entire "error term" under $\frac 1 d$.
For example, let's try it for the divisor 11. With the general algorithm, we would need $k = 32 + \lceil log_2 11 \rceil = 36$. But what if we choose k = 35 instead? 235 + 1 is a multiple of 11, so we have e = 1, and we compute:
$\frac e d \times \frac n {2^k} = \frac 1 d \times \frac n {2^{35}} < \frac 1 d$
So k = 35 forces the error term to be less than $\frac 1 d$, and therefore k = 35 is a good enough approximation. This is good news, because then $m = \lceil \frac {2^{35}} {11} \rceil = 3123612579 < 2^{32}$, so our magic number fits in 32 bits, and we don't need to worry about overflow! We can avoid the subtraction, addition, and extra shifting in the general algorithm. Indeed, clang outputs:
The code for dividing by 11 is shorter than for dividing by 7, because a multiple of 11 happens to be very close to a power of 2. This shows the way to an improved algorithm: We can simply try successive powers of 2, from 32 up to $32 + \lfloor log_2 d \rfloor$, and see if any of them happen to be close enough to a multiple of d to force the error term below $\frac 1 d$. If so, the corresponding magic number fits in 32 bits and we can generate very efficient code. If not, we can always fall back to the general algorithm.
The power 32 will work if $\frac e d \leq \frac 1 d$, the power 33 will work if $\frac e d \leq \frac 2 d$, the power 34 will work if $\frac e d \leq \frac 4 d$, etc., up to $32 + \lfloor log_2 d \rfloor$, which will work if $\frac e d \leq \frac 1 2$. By "chance", we'd expect this last power to work half the time, the previous power to work 25% of the time, etc. Since we only need one, most divisors actually should have an efficient, 32 bit or fewer magic number. The infinite series $\frac 1 2 + \frac 1 4 + \frac 1 8$ sums to 1, so our chances get better with increasing divisors.
It's interesting to note that if a divisor d has one of these more efficient magic numbers for a power $k < 32 + \lceil log_2 d \rceil$, it also has one for all higher powers. This is easy to see: if 2k + e is a multiple of d, then 2k+1 + 2e is also a multiple of d.
$\frac e d \times \frac n {2^k} \leq \frac 1 d \implies \frac {2e} d \times \frac n {2^{k+1}} \leq \frac 1 d $
This is good news. It means that we only have to check one case, $ \lceil \frac {2^{32 + \lfloor log_2 d \rfloor}} d \rceil$ (a 32 bit value) to see if there is a more efficient magic number, because if any smaller power works, that one works too. If that that power fails, we can go to the 33 bit number, which we know must work. This is useful information in case we are computing magic numbers at runtime.
Still, gcc and LLVM don't settle for just any magic number - both try to find the smallest magic number. Why? There's a certain aesthetic appeal in not using bigger numbers than necessary, and most likely the resulting smaller multiplier and smaller shifts are a bit faster. In fact, in a very few cases, the resulting shift may be zero! For example, the code for diving by 641:
No shifts at all! For this to happen, we must have $\frac e d \le \frac 1 d$, which of course means that e = 1, so 641 must evenly divide 232 + 1. Indeed it does.
This inspires a way to find the other "super-efficient" shiftless divisors: compute the factors of 232 + 1. Sadly, the only other factor is 6700417. I have yet to discover an occasion to divide by this factor, but if I do, I'll be ready.
So that's how it works
Did you skip ahead? It's OK. Here's the summary.
Every divisor has a magic number, and most have more than one! A magic number for d is nothing more than a precomputed quotient: a power of 2 divided by d and then rounded up. At runtime, we do the same thing, except backwards: multiply by this magic number and then divide by the power of 2, rounding down. The tricky part is finding a power big enough that the "rounding up" part doesn't hurt anything. If we are lucky, a multiple of d will happen to be only slightly larger than a power of 2, so rounding up doesn't change much and our magic number will fit in 32 bits. If we are unlucky, well, we can always fall back to a 33 bit number, which is almost as efficient.
I humbly acknowledge the legendary Guy SteeleHenry Warren (must have been a while) and his book Hacker's Delight, which introduced me to this line of proof. (Except his version has, you know, rigor.)
If you immediately blurted out "xisanarrayofthreeconstpointerstofunctionsreturningpointerstoarraysoffivepointerstofunctionstakingintreturningchar", and your last name doesn't end with "itchie," then chances are you used my new website:
www.cdecl.org
Yes, the venerable cdecl - the C gibberish to English translator - is now online. With AJAX! Every C declaration will be as an open book to you! Your coworkers' scruffy beards and suspenders will be nigh useless!
Write C casts and declarations in plain English! Write plain English in the chicken scratchings and line noise we call C! The possibilities are twain!
Allows you to generate permalinks, so you can send hilarious declarations to your friends, or add them gratuitously to your blog
A note on licensing. The cdecl readme states:
You may well be wondering what the status of cdecl is. So am I. It was twice posted to comp.sources.unix, but neither edition carried any mention of copyright. This version is derived from the second edition. I have no reason to believe there are any limitations on its use, and strongly believe it to be in the Public Domain.
I hereby place my blocks changes to cdecl in the public domain. The cdecl source code, including my changes, is available for download on the site.
For those who like their punchlines first: std::string is designed to allow copy-on-write. But once operator[] is called, that string is ruined for COW forevermore. The reason is that it has to guard against a future write at any time, because you may have stashed away the internal pointer that operator[] returns - a feature that you surely know better than to use, but that costs you nevertheless.
The C++ standard string class is std::string. Here's a string containing 10 megabytes of the letter 'x':
#include <string>
using std::string;
int main(void) {
string the_base(1024 * 1024 * 10, 'x');
}
Big string. Now let's make a hundred copies, one by one:
#include <string>
using std::string;
int main(void) {
string the_base(1024 * 1024 * 10, 'x');
for (int i = 0; i < 100; i++) {
string the_copy = the_base;
}
}
This runs in .02 seconds, which is very fast. Suspiciously fast! This old iMac can't schlep a gigabyte of data in two hundredths of a second. It's using copy-on-write.
So let's write and measure the copy:
#include <string>
using std::string;
int main(void) {
string the_base(1024 * 1024 * 10, 'x');
for (int i = 0; i < 100; i++) {
string the_copy = the_base;
the_copy[0] = 'y';
}
}
The program now runs in 2.5 seconds. These scant 100 writes resulted in a 100x slowdown. Not surprising: it's exactly what we would expect from a COW string.
the_copy[0] returns a reference to a char. But maybe we aren't going to write into it - perhaps we only want to read. How can these copy-on-write strings know when the write occurs, so they can copy? The answer is that they cannot - they must be pessimistic and assume you will write, even if you never do. We can trick it: don't assign anything, and still see the performance hit:
#include <string>
using std::string;
int main(void) {
string the_base(1024 * 1024 * 10, 'x');
for (int i = 0; i < 100; i++) {
string the_copy = the_base;
the_copy[0];
}
}
No writes! Just a read! But same performance as before. This isn't copy on write - it's copy on read!
Things get even worse. operator[] returns a reference: basically a sugary pointer. You can read from it or write to it. Or you can be a jerk and just hang onto it:
In case that's not clear, we made a string, stashed away a reference to the first character, copied the string, and then wrote to the string's guts. The write is just a normal store to a memory location, so the poor string is caught completely unaware. If the copy-on-write were naive, then we would have modified both the original and the copy.
Oh man, is that evil. But the string's got to be paranoid and guard against it anyways - in fact, the C++ standard explicitly calls out this case as something that has to work! In other words, when you get a reference to a char inside a string, the string is tainted. It can never participate in copy-on-write again, because you just might have stashed away the internal pointer it handed back, and write into the string as a completely unexpected time.
Of course you know better than to hang onto internal pointers. You probably don't need this feature. But you pay for it anyways:
#include <string>
using std::string;
int main(void) {
string the_base(1024 * 1024 * 10, 'x');
the_base[0];
for (int i = 0; i < 100; i++) {
string the_copy = the_base;
}
}
This takes the 2.5 seconds. Just one silly read wrecked all of the COW machinery for all the future copies. You're paying for writes that never come!
Could the C++ standard have fixed this? Sure - the C++ standard goes into great detail about when iterators and references into strings are invalidated, and all it would have taken would be to add the copy constructor and operator=() to the list of reference-invalidating functions (section 23.1.5, for those who are following along in the standard). A second option would have been to declare that operator=() invalidates existing references for writing, but not for reading. But the standards committee preferred simplicity, convenience and safety to performance - uncharacteristically, if you'll forgive a smidgen of editorializing.
If you call a reference-invalidating function, you can, in principle, get back in the COW fast lane. Although GNU STL does not take advantage of this in all cases, it does when resizing strings:
#include <string>
using std::string;
int main(void) {
string the_base(1024 * 1024 * 10, 'x');
the_base[0];
the_base.push_back('x');
for (int i = 0; i < 100; i++) {
string the_copy = the_base;
}
}
Allowing the string to modify itself allowed it to know that any previous references were invalidated. We're fast again! It's called a COW, and it's not about to blow it now.
The moral is that you should avoid using operator[], the at() function, iterators, etc. to read from a non-const string - especially a long string - if it may be copied in the future. If you do use these functions, you risk paying for a write that you don't make, and for hanging onto an internal pointer that you released. Unfortunately, there's no good function for just reading from a non-const string. You can do it by adding a crazy cast:
#include <string>
using std::string;
int main(void) {
string the_base(1024 * 1024 * 10, 'x');
const_cast<const string &>(the_base)[0];
for (int i = 0; i < 100; i++) {
string the_copy = the_base;
}
}
This hits the fast path too.
Scene. I hope you enjoyed this post. As usual the point is not to rag on C++, but to explore aspects of its design that, for whatever reason, tilt a tradeoff away from performance.
Hooray, it's Hex Fiend 2, a nearly complete rewrite of Hex Fiend that incorporates even better techniques for working with big files. Hex Fiend is my fast and clever hex editor for Mac OS X.
This app is about exploring the implementation of standard desktop UI features in the realm of files too large to fully read into main memory. Is it possible to do copy and paste, find and replace, undo and redo, on a document that may top a hundred gigabytes, and make it feel natural? Where do we run into trouble?
More on that later. For now, here's what's better about Hex Fiend 2:
It's embeddable. The most requested feature was "I want a hex view in my app." Now it's really easy: Hex Fiend 2 is built as a relatively slim shell on top of a bundle-embeddable .framework. There's a real API, sample code, and everything. See the Developer section of the Hex Fiend page.
It's faster. All around. Text rendering is speedier, and the backing data representation more efficient. It needs less I/O too.
The save algorithm is especially improved. For example, inserting one byte at the beginning of a 340 MB file and hitting Save would take 52 seconds and 340 additional MB of temporary disk space with Hex Fiend. In Hex Fiend 2 it's reduced to 22 seconds and requires no temporary disk space.
Better UI. It supports discontiguous selection. Scroll-wheel scrolling no longer feels weird. You can group the bytes into blocks (credit to Blake), and you can hide and show different views (thanks to bbum). The big dorky line number view now shrinks to fit. The data inspector panel is inline. It has Safari-style inline find and replace and "pop out" selection highlighting.
Long operations support progress reporting, cancellation, and don't block the UI. For example, find and replace now has a progress bar and a cancel button, and you can keep using your document (or others) while it works.
Longstanding bugfixes. Backwards searching is now optimized. Certain coalesced undo bugs have been addressed. There's some basic cross-file dependency tracking.
C++ was designed to ensure you "only pay for what you use," and at that it is mostly successful. But it's not entirely successful, and I thought it might be interesting to explore some counterexamples: C++ features you don't use but still negatively impact performance, and ways in which other languages avoid those issues.
So here's the first episode of I Didn't Order That, So Why Is It On My Bill, to be continued until I can't think of any more.
Inline Functions
The C++ standard says this:
A static local variable in an extern inline function always refers to the same object.
In other words, static variables in inline functions work just like static variables in any function. That's reasonable, because that's probably what you want. That's what statics are for, after all.
But wait, it also says this:
An inline function with external linkage shall have the same address in all translation units.
That's borderline silly. Who cares what the address of the function is? When's the last time you used the function pointer address for anything except calling it? Dollars to donuts says never. You aren't using a function pointer as a hash table key. You aren't comparing the same function via pointers from different files. And if you did, you'd probably have the good sense to ensure the functions are defined exactly once (i.e. not inline). You can easily live without this feature.
So hopefully I've established that you don't use this feature. Now I have to show how you're paying for it anyways. Well, this feature complicates linking. Ordinarily, there should be only one copy of a function, and if the linker finds more than one it gives you a multiple definition error. But with inline functions, the compiler is expected to generates multiple copies of the code and it's up to the linker to sort it out. See vague linkage.
So the linker has more work to do, and link time is increased. Again, who cares? Linking occurs after compilation, and I promised you a runtime cost. But ah - link time is runtime when we're using dynamic libraries!
Every time you start up a program, the linker has to make sure that your implementation of vector<int>::capacity() has the same address as the vector<int>::capacity() defined in libWhoGivesAHoot.dylib just in case you decide to go and compare their function pointers.
And it gets a little worse. You know how class templates have to live in header files? The function definition goes right there in the class declaration, and that makes them inline automatically. So nearly every function in a template gets this inline uniquing treatment. Every template function in a class that cannot or should not be inlined - because its address is taken, because it is recursive, because you're optimizing for size, or simply because it's too darn big and inlining is counterproductive - will incur a launch time cost.
The situation is dire enough that gcc added a "-fvisibility-inlines-hidden" flag. This is a minor violation of the C++ standard, but will improve launch time in cases with a lot of dynamic libraries. In other words, this flag says: I'm not using this feature, please take it off my bill.
C does not have this problem. Why not? C (in the C99 standard) has very different semantics for inline functions. To oversimplify a bit, a C99 inline function acts as sort of an alias for a real function, which must be defined once and only once. Furthermore, inline functions can't have static variables, or have their addresses taken. This approach is more limiting, but doesn't require the linker to bend over backwards, and so avoids the performance penalty of the C++ approach.
As any usability expert will tell you, the foundation of sound web page design is rounded corners. Their smooth curves lend an organic, almost sensual feel to a site, while other pages are un-navigable morasses of right angles.
Rounded corners are easy with tables and images! But tables make your page Web 2.0-incompatible, so most browsers cannot render it.
So when I decided to get some roundy corners for myself, I looked around, and the best I was able to find was Nifty Corners. There's a lot to like about Nifty Corners, but look what happens if you try to make them overlap or put them on a, say, not-fixed-color background:
Notice that the corners of the boxes suffer. The problem is that the area around the corner cannot be drawn transparently - it needs to be over a fixed color. Browser specific extensions would be perfect if they weren't browser specific.
But I like crazy backgrounds and overlapping boxes. So in a half-hearted effort for geek cred, here's how my roundy corners worked.
This is a div:
This is a bordered div:
This is a thickly bordered div:
This is a thickly bordered div with differently colored borders:
This is a div bordered only on the left and right:
This is a div bordered more thickly on the right:
Closer:
Closer:
Contact:
This is a bunch of divs in a stack:
This is a bunch of divs in a stack with different right border widths:
This is a bunch of divs in a stack with different right border widths, set to float right:
Smaller:
Smaller:
One pixel high!
Make the left border pastel red to soften the edge. Tweak the border widths to get the desired curve. Add a solid div on top:
Four corners:
Connect the top and bottom with one div each:
Add a div in the center where stuff goes:
And the stuff doth go:
Yo mama!
Broken apart to show some of the pieces:
Yo mama!
These overlap nicely (at least in Safari, IE6, and Firefox), respect z-order, and work well with non-solid backgrounds. They do not require images, tables, or JavaScript.
Yo mama!
No, yo mama!
Touché!
Hey! Flexible widths!
Resize me!
But but but...
Isn't that, like, a humongous flood of markup? Won't the page take a long time to download?
Well, I worried about that too. But happily, all modern browsers support gzip compression - and boy does it work! Even though my last posting with comments is 382 KB in size, you only need to download 19.8 KB (Mac users can look in Safari's Activity Viewer for the download size). So it ends up being smaller than, say, Yahoo!'s home page - and that's just the HTML, not even counting all of its images. As a result, the page loads quite fast.
Well, don't all those divs make the page unmaintainable?
Yeah, I suppose so. I use a script to generate these boxes, so the source is readable to me - even if the generated HTML isn't.
Buzz is leaving Apple, has already left. Buzz joined Apple two months after I joined, on the same team. He was the first candidate I ever interviewed, although I can't remember what I asked him. Without Buzz's encouragement and inspiration, I'd have never started this blog, and he was first to link to me. So thank you and farewell, Buzz.
On another thread, I've fixed the Angband screensaver to remember the last character it played with. The user defaults had to be synchronized. Thanks to everyone who pointed this out.
Where isst it? So it iss back - so fissh, the fish, raw and wriggling, he hasst brought its back!
Angband, the Hells of Iron, yest, the ancient ASCII roguelike, child spawn of Moria and VMS, it iss here once more. We wants it!
You hasst not seen it, Angband? But perhapss you have seen one like it, the filthy, filthy NetHack, yess, full of such stupids and jokeses, and no Smeagol! We hates it for ever! But we loves Angband, yess, Angband has Smeagol and the fat hobbitses and yes, it has my preciouss! We loves it, Angband!
We hass thought it lost. When OS X was a little child and hungry for software, we knows how it calls to fissh. We knows how fissh missed Angband, dearly missed Smeagol, yes. And we knows how fissh stoles it, and worked his tricksy little magic, so he could go down into a Carbonized Angband on OS X. And we knows fissh did, and it was easy, Carbon madess it simple.
But fissh hasst brought it to Cocoa, now, all fresh and it glitterses so subpixel pretty with Quartz, and resizesss so smooth, and animates with pretty graphics! So precious to fissh.
And ssuch love for Angband so fissh made a borg screensaveres! So now you can visits Smeagol and wring the filthy little neck of Saruman and murderes the fat Morgoth in your sleep! The screensaveres, yes!
Goes there now, fat hobbitses! The game and the screensaveres and the source codess! Angband need you, yess!
"That's a lot of cores.And while 80-core floating point monsters like that aren't likely to show up in an iMac any time soon, multicore chips in multiprocessor computers are here today. Single chip machines are so 2004. Programmers better get crackin'. The megahertz free ride is over - and we have work to do."
There, that's the noisome little pitch everyone's been spreading like so much thermal paste. As if multiprocessing is something new! But of course it's not - heck, I remember Apple shipping dualies more than ten years ago, as the Power Macintosh 9500. Multiprocessing is more accessible (read: cheaper) now, but it's anything save new. It's been around long enough that we should have it figured out by now.
So what's my excuse? I admit it - I don't get multiprocessing, not, you know, really get it, and that's gone on long enough. It's time to get to the bottom of it - or if not to the bottom, at least deep enough that my ears start popping.
Threadinology
Where to start, where to start...well, let's define our terms. Ok, here's the things I mean when I say the following, uh, things:
Threads are just preemptively scheduled contexts of execution that share an address space. But you already know what threads are. Frankly, for my purposes, they're all pretty much the same whether you're using Objective-C or C++ or Java on Mac OS X or Linux or Windows...
Threading means creating multiple threads. But you often create multiple threads for simpler control flow or to get around blocking system calls, not to improve performance through true simultaneous execution.
Multithreading is the physically simultaneous execution of multiple threads for increased performance, which requires a dualie or more. Now things get hard.
Yeah, I know. "Multithreading is hard" is a cliché, and it bugs me, because it is not some truism describing a fundamental property of nature, but it's something we did. We made multithreading hard because we optimized so heavily for the single threaded case.
What do I mean? Well, processor speeds outrun memory so much that we started guessing at what's in memory so the processor doesn't have to waste time checking. "Guessing" is a loaded term; a nicer phrase might be "make increasingly aggressive assumptions" about the state of memory. And by "we," I mean both the compiler and the processor - both make things hard, as we'll see. We'll figure this stuff out - but they're going to try to confuse us. Oh well. Right or wrong, this is the bed we've made, and now we get to lie in it.
while (1) {
x++;
y++;
}
x should always be at least as big as y, right? Right?
Blah blah. Let's look at some code. We have two variables, variable1 and variable2, that both start out at 0. The writer thread will do this:
Writer thread
while (1) {
variable1++;
variable2++;
}
They both started out at zero, so therefore variable1, at every point in time, will always be the same as variable2, or larger - but never smaller. Right?
The reader thread will do this:
Reader thread
while (1) {
local2 = variable2;
local1 = variable1;
if (local2 > local1) {
print("Error!");
}
}
That's odd - why does the reader thread load the second variable before the first? That's the opposite order from the writer thread! But it makes sense if you think about it.
See, it's possible that variable1 and/or variable2 will be incremented by the writer thread between the loads from the reader thread. If variable2 gets incremented, that doesn't matter - variable2 has already been read. If variable1 gets incremented, then that makes variable1 appear larger. So we conclude that variable2 should never be seen as larger than variable1, in the reader thread. If we loaded variable1 before variable2, then variable2 might be incremented after the load of variable1, and we would see variable 2 as larger.
Analogy to the rescue. Imagine some bratty kid playing polo while his uptight father looks on with a starched collar and monocle (which can only see one thing at a time, and not even very well, dontcha know). The kid smacks the ball, and then gallops after it, and so on. Now the squinting, snobby father first finds the ball, then looks around for his sproggen. But! If in the meantime, the kid hits it and takes off after it, Dad will find the kid ahead of where he first found the ball. Dad doesn't realize the ball has moved, and concludes that his budding athlete is ahead of the ball, and running the wrong way! If, however, Dad finds the kid first, and then the ball, things will always appear in the right order, if not the right place. The order of action (move ball, move kid) has to be the opposite from the order of observation (find kid, find ball).
Threadalogy
So we've got two threads operating on two variables, and we think we know what'll happen. Let's try it out, on my G5:
fish ) ./a.out
0 failures (0.0 percent of the time) in 0.1 seconds
How do we know that the reader thread won't see a variable in some intermediate state, midway through being updated? We have to know that these particular operations are atomic. On PowerPC and x86 machines, 32 bit writes to aligned addresses are guaranteed atomic. Other types of memory accesses are not always atomic - in particular, 64 bit writes (say, of a double precision floating point value) on a 32 bit PowerPC are not atomic. We have to check the documentation to know.
So, we're done?
Our expectations were confirmed! The writer thread ordered its writes so that the first variable would always be at least as big as the second, and the reader thread ordered its reads the opposite way to preserve that invariant, and everything worked as planned.
But we might just be getting lucky, right? I mean, if thread1 and thread2 were always scheduled on the same processor, then we wouldn't see any failures - a processor is always self-consistent with how it appears to order reads and writes. In other words, a particular processor remembers where and what it pretends to have written, so if you read from that location with that same processor, you get what you expect. It's only when you read with processor1 from the same address where processor2 wrote - or pretended to write - that you might get into trouble.
So let's try to force thread1 and thread2 to run on separate processors. We can do that with the utilBindThreadToCPU() function, in the CHUD framework. That function should never go in a shipping app, but it's useful for debugging. Here it is:
fish ) ./a.out
0 failures (0.0 percent of the time) in 0.1 seconds
NOW are we done?
Still no failures. Hmm... But wait - processors operate on cache lines, and variable1 and variable2 are right next to each other, so they probably share the same cache line - that is, they get brought in together and treated the same by each processor. What if we separate them? We'll put one on the stack and leave the other where it is.
So now, one variable is way high up on the stack and the other is way down low in the .data section. Does this change anything?
fish ) ./a.out
0 failures (0.0 percent of the time) in 0.1 seconds
Still nothing! I'm not going to have an article after all! Arrrghhh **BANG BANG BANG BANG**
fish ) ./a.out
0 failures (0.0 percent of the time) in 0.1 seconds
fish ) ./a.out
0 failures (0.0 percent of the time) in 0.1 seconds
fish ) ./a.out
0 failures (0.0 percent of the time) in 0.1 seconds
fish ) ./a.out
50000000 failures (100.0 percent of the time) in 0.1 seconds
Hey, there it is! Most of the time, every test passes, but that last time, every test failed.
Our Enemy the Compiler
The lesson here is something you already knew, but I'll state it anyways: Multithreading bugs are very delicate. There is a real bug here, but it was masked by the fact that the kernel scheduled them on the same processor, and then by the fact that the variables were too close together in memory, and once those two issues were removed, (un)lucky timing usually masked the bug anyways. In fact, if I didn't know there was a bug there, I'd never have found it - and I still have my doubts!
So first of all, why would every test pass or every test fail? If there's a subtle timing bug, we'd expect most tests to pass, with a few failing - not all or nothing. Let's look at what gcc is giving us for the reader function:
lis r9,0x2fa
ori r2,r9,61568
mtctr r2
L8:
bdnz L8
lis r2,0x2fa
ori r2,r2,61568
mullw r2,r0,r2
Hey! The entire extent of that big long 50 million iteration loop has been hoisted out, leaving just the blue bits - essentially fifty million no-ops. Instead of adding one or zero each time through the loop, it calculates the one or zero once, and then multiplies it by 50 million.
gcc is loading from variable1 and variable2 exactly once, and comparing them exactly once, and assuming their values do not change throughout the function - which would be a fine assumption if there weren't also other threads manipulating those variables.
This is an example of what I mentioned above, about the compiler making things difficult by optimizing so aggressively for the single threaded case.
Well, you know the punchline - to stop gcc from optimizing aggressively, you use the volatile keyword. So let's do that:
fish ) ./a.out
12462711 failures (24.9 percent of the time) in 3.7 seconds
It's much slower (expected, since volatile defeats optimizations), but more importantly, it fails intermittently instead of all or nothing. Inspection of the assembly shows that gcc is generating the straightforward sequence of loads and stores that you'd expect.
Our Enemy the Processor
Is this really the cross-processor synchronization issues we're trying to investigate? We can find out by binding both threads to the same CPU:
fish ) ./a.out
0 failures (0.0 percent of the time) in 0.4 seconds
The tests pass all the time - this really is a cross-processor issue.
So somehow variable2 is becoming larger than variable1 even though variable1 is always incremented first. How's that possible? It's possible that the writer thread, on processor 0, is writing in the wrong order - it's writing variable2 before variable1 even though we explicitly say to write variable1 first. It's also possible that the reader thread, on processor 1, is reading variable1 before variable 2, even though we tell it to do things in the opposite order. In other words, the processors could be reading and writing those variables in any order they feel like instead of the order we tell them to.
Pop and Lock?
What's the usual response to cross-processor synchronization issues like this? A mutex! Let's try it.
fish ) ./a.out
0 failures (0.0 percent of the time) in 479.5 seconds
It made the tests pass, all right - but it was 130 times slower! A spinlock does substantially better, at 20 seconds, but that's still 440% worse than no locking - and spinlocks won't scale. Surely we can do better.
Even the kitchen
Our problem is this: our processors are doing things in a different order than we tell them to, and not informing each other. Each processor is only keeping track of its own shenanigans! For shame! We know of two super-horrible ways to fix this: force both threads onto the same CPU, which is a very bad idea, or to use a lock, which is a very slow idea. So what's the right way to make this work?
What we really want is a way to turn off the reordering for that particular sequence of loads and stores. They don't call it "turn off reordering", of course, because that might imply that reordering is bad. So instead they call it just plain "ordering". We want to order the reads and writes. Ask and ye shall receive - the mechanism for that is called a "memory barrier".
And boy, does the PowerPC have them. I count at least three: sync, lwsync, and the hilariously named eieio. Here's what they do:
sync is the sledgehammer of the bunch - it orders all reads and writes, no matter what. It works, but it's slow.
lwsync (for "lightweight sync") is the newest addition. It's limited to plain ol' system memory, but it's also faster than sync.
eieio ("Enforce In-Order execution of I/O") is weird - it orders writes to "device" memory (like a memory mapped peripheral) and regular ol' system memory, but each separately. We only care about system memory, and IBM says not to use eieio just for that. Nevertheless, it should still order our reads and writes like we want.
Because we're not working with devices, lwsync is what we're after. Processor 0 is writing variable2 after variable1, so we'll insert a memory barrier to prevent that:
Do we need a memory barrier after the write to variable2 as well? No - that would guard against the possibility of the next increment landing on variable1 before the previous increment hits variable2. But the goal is to make sure that variable1 is larger than variable2, so it's OK if that happens.
fish ) ./a.out
260 failures (0.0 percent of the time) in 0.9 seconds
So we reduced the failure count from 12462711 to 260. Much better, but still not perfect. Why are we still failing at times? The answer, of course, is that just because processor 0 writes in the order we want is no guarantee that processor1 will read in the desired order. Processor 1 may issue the reads in the wrong order, and processor 0 would write in between those two reads. We need a memory barrier in the reader thread, to force the reads into the right order as well:
fish ) ./a.out
0 failures (0.0 percent of the time) in 4.2 seconds
That did it!
The lesson here is that if you care about the order of reads or writes by one thread, it's because you care about the order of writes or reads by another thread. Both threads need a memory barrier. Memory barriers always come in pairs, or triplets or more. (Of course, if both threads are in the same function, there may only be one memory barrier that appears in your code - as long as both threads execute it.)
This should not come as a surprise: locks have the same behavior. If only one thread ever locks, it's not a very useful lock.
31 Flavors
What's that? You noticed that the PowerPC comes with three different kinds of memory barriers. Right - as reads and writes get scheduled increasingly out of order, the more expensive it becomes to order them - so the PowerPC allows you to request various less expensive partial orderings, for performance. Processors that schedule I/O out of order more aggressively offer even more barrier flavors. At the extreme end is the DEC Alpha, that sports read barriers with device memory ordering, read barriers without, write barriers with, write barriers without, page table barriers, and various birds in fruit trees. The Alpha's memory model guarantees so little that it is said to define the Linux kernel memory model - that is, the set of available barriers in the kernel source match the Alpha's instruction set. (Of course, many of them get compiled out when targetting a different processor.)
Actually - and here my understanding is especially thin - while x86 is strongly ordered in general, I believe that Intel has managed to slip some weakly ordered operations in sideways, through the SIMD unit. These are referred to as "streaming" or "nontemporal" instructions. And when writing to specially tagged "write combining" memory, like, say, memory mapped VRAM, the rules are different still.
And on the other end, we have strongly ordered memory models that do very little reordering, like the - here it comes - x86. No matter how many times I run that code, even on a double-dualie Intel Mac Pro, I never saw any failures. Why not? My understanding (and here it grows fuzzy) is that early multiprocessing setups were strongly ordered because modern reordering tricks weren't that useful - memory was still pretty fast, y'know, relatively speaking, so there wasn't much win to be had. So developers blithely assumed the good times would never end, and we've been wearing the backwards compatibility shackles ever since.
But that doesn't answer the question of why x86_64, y'know, the 64 bit x86 implementation in the Core 2s and all, isn't more weakly ordered - or at least, reserve the right to be weaker. That's what IA64 - remember Itanium? - did: early models were strongly ordered, but the official memory model was weak, for future proofing. Why didn't AMD follow suit with x86_64? My only guess (emphasis on guess) is that it was a way of jockeying for position against Itanium, when the 64 bit future for the x86 was still fuzzy. AMD's strongly ordered memory model means better compatibility and less hair-pulling when porting x86 software to 64 bit, and that made x86_64 more attractive compared to the Itanium. A pity, at least for Apple, since of course all of Apple's software runs on the weak PowerPC - there's no compatibility benefit to be had. So it goes. Is my theory right?
Makin' a lock, checkin' it twice
Ok! I think we're ready to take on that perennial bugaboo of Java programmers - the double checked lock. How does it go again? Let's see it in Objective-C:
+ getSharedObject {
static id sharedObject;
if (! sharedObject) {
LOCK;
if (! sharedObject) {
sharedObject = [[self alloc] init];
}
UNLOCK;
}
return sharedObject;
}
What's the theory? We want to create a single shared object, exactly once, while preventing conflict between multiple threads. The hope is that we can do a quick test to avoid taking the expensive lock. If the static variable is set, which it will be most of the time, we can return the object immediately, without taking the lock.
Sometimes memory barriers are needed to guard against past or future reads and writes that occur in, say, the function that's calling your function. Reordering can cross function and library boundaries!
This sounds good, but of course you already know it's not. Why not? Well, if you're creating this object, you're probably initializing it in some way - at the very least, you're setting its isa (class) pointer. And then you're turning around and writing it back to the sharedObject variable. But these can happen in any order, as seen from another processor - so when the getSharedObject method is called from some other processor, it can see the sharedObject variable as set, and happily return the object before its class pointer is even valid. Cripes.
But now you know we have the know-how to make this work, no? How? The problem is that we need to order the writes within the alloc and init methods relative to the write to the sharedObject variable - the alloc and init writes must come first, the write to sharedObject last. So we store the object into a temporary local variable, insert a memory barrier, and then copy from the temporary to the shared object. This time, I'll use Apple's portable memory barrier function:
+ getSharedObject {
static id sharedObject;
if (! sharedObject) {
LOCK;
if (! sharedObject) {
id temp = [[self alloc] init];
OSMemoryBarrier();
sharedObject = temp;
}
UNLOCK;
}
return sharedObject;
}
There! Now we're guaranteed that the initializing thread really will write to sharedObject after the object is fully initialized. All done.
Hmm? Oh, nuts! I forgot my rule - write barriers come in pairs. If thread A initializes the object, it goes through a memory barrier, but if thread B then comes along, it will see the object and return it without any barrier at all. Our rule tells us that something is wrong, but what? Why's that bad?
Well, thread B's going to do something with the shared object, like send it a message, and that requires at the very least accessing the isa class pointer. But we know the isa pointer really was written to memory first, before the sharedObject pointer, and thread B got ahold of the sharedObject pointer, so logically, the isa pointer should be written, right? The laws of physics require it! Isn't that, like, you put an object in a box and hand it to me, and then I open the box to find that you haven't put something into it yet! It's a temporal paradox!
The answer is that, yes, amazingly, dependent reads like that can be performed seemingly out of order, but not on any processors that Apple ships. I've only heard of it happening in the - you guessed it - the Alpha. Crazy, huh?
So where should the memory barrier go? The goal is to order future reads - reads that occur after this sharedObject function returns - against the read from the sharedObject variable. So it's gotta go here:
+ getSharedObject {
static id sharedObject;
if (! sharedObject) {
LOCK;
if (! sharedObject) {
id temp = [[self alloc] init];
OSMemoryBarrier();
sharedObject = temp;
}
UNLOCK;
}
OSMemoryBarrier();
return sharedObject;
}
Now, this differs slightly from the usual solution, which stores the static variable into a temporary in all cases. However, for the life of me I can't figure out why that's necessary - the placement of the second memory barrier above seems correct to me, assuming the compiler doesn't hoist the final read of sharedObject above the memory barrier (which it shouldn't). If I screwed it up, let me know how, please!
Do we want it?
That second memory barrier makes the double checked lock correct - but is it wise? As we discussed, it's not technically necessary on any machine you or I are likely to encounter. And, after all, it does incur a real performance hit if we leave it in. What to do?
The Linux kernel defines a set of fine-grained barrier macros that get compiled in or out appropriately (we would want a "data dependency barrier" in that case). You could go that route, but my suggestion is to just leave a semi-standard comment to help you locate these places in the future. That will help future-proof your code, but more importantly, it forces you to reason carefully about the threading issues, and to record your thoughts. You're more likely to get it right.
+ getSharedObject {
static id sharedObject;
if (! sharedObject) {
LOCK;
if (! sharedObject) {
id temp = [[self alloc] init];
OSMemoryBarrier();
sharedObject = temp;
}
UNLOCK;
}
/* data dependency memory barrier here */
return sharedObject;
}
Wrapping up! Skimmers skip to here.
Now are we done?
I think so, Mr. Subheading. Let's see if we can summarize all this:
Locks are like tanks - powerful, slow, safe, expensive, and prone to getting you stuck.
The compiler and the processor both conspire to defeat your threads by moving your code around! Be warned and wary! You will have to do battle with both.
Even so, it is very easy to mask serious threading bugs. We had to work hard, even in highly contrived circumstances, to get our bug to poke its head out even occasionally.
Ergo, testing probably won't catch these types of bugs. That makes it more important to get it right the first time.
Locks are the heavy tanks of threading tools - powerful, but slow and expensive, and if you're not careful, you'll get yourself stuck in a deadlock.
Memory barriers are a faster, non-blocking, deadlock free alternative to locks. They take more thought, and aren't always applicable, but your code'll be faster and scale better.
Memory barriers always come in logical pairs or more. Understanding where the second barrier has to go will help you reason about your code, even if that particular architecture doesn't require a second barrier.
Further reading
Seriously? You want to know more? Ok - the best technical source I know of is actually a document called "memory-barriers.txt" that comes with the Linux kernel source. You can get it here. Thanks to my co-worker for finding it and directing me to it.
Things I wanna know
I'm still scratching my head about some things. Maybe you can help me out.
Why is x86_64 strongly ordered? Is my theory about gaining a competitive edge over Itanium reasonable?
Is my double checked lock right, even though it doesn't use a temporary variable in the usual place?
What's up with the so-called "nontemporal" streaming instructions on x86?
0xF4EENovember 24th, 2006Hex Fiend 1.1.1 is now available open source under a BSD-style license. Hex Fiend is my fast and clever free open source hex editor for Mac OS X.
I hope you find Hex Fiend useful for whatever purpose, but if you are interested in contributing changes on an ongoing basis, I'll be happy to grant Subversion commit privileges to some interested developers who submit quality patches. There is a wiki aimed at developers accessible from the page, but daily builds, mailing lists, or discussion boards are also a possibility. You can contact me at the e-mail address at the bottom of the Hex Fiend page if you are interested in any of these.
Version 1.1.1 has some important bug fixes (see the release notes), so you should upgrade even if you are not interested in the source.
Mac OS 9 and NEXTSTEP were like two icy comets wandering aimlessly in space. Neither was really going anywhere in particular. And then, BANG! They collide, stick wetly together, spinning wildly! Thus was born Mac OS X - or so the legend goes.
How do you take these two comets, err, operating systems, and make a unified OS out of them? On the one hand, you have the procedural classic Macintosh Toolbox, and on the other you have object oriented OPENSTEP, as different as can be - and you're tasked with integrating them, or at least getting some level of interoperability. What a headache!
You might start by finding common ground - but there isn't much common ground, so you have to invent some, and you call it (well, part of it) CoreFoundation. Uh, let's abbreviate CoreFoundation "CF" from now on. CoreFoundation will "sit below" both of these APIs, and provide functions for strings and dates and other fundamental stuff, and the shared use of CF will serve as a sort of least common demoninator, not only for these two APIs but also for future APIs. These two APIs will be able to talk to each other, and to future APIs, with CF types.
Ok, so the plan is to make these two APIs, the Mac Toolbox and OPENSTEP, use CF. Adding CF support to the Mac Toolbox is not that big a deal, because the Mac Toolbox APIs have to change anyways, to become Carbon. But the OPENSTEP APIs don't have the same sort of problems, and shouldn't have to change much to become Cocoa.
Like, for example, the Toolbox uses Pascal strings, and those have unfortunate length limitations and ignorance of Unicode, so we want to get rid of them - so we might as well use the interoperable replacement as the native string type in Carbon. But OPENSTEP's NSString is already pretty nice. It would be a shame to have to make CFString replacements for all those Cocoa APIs that take and return NSStrings, just for interoperability with Carbon.
Rough Draft
So the solution is obvious, right? Just make NSString methods to convert to and from CFStrings.
So whenever you want to talk to Carbon, you get a CFStringRef from your NSString, and whenever you get a CFStringRef back from Carbon, you make an NSString out of it. Simple! But this isn't what Apple did.
Second Revision
"Hey," you say. Some of you say. "I know what Apple did. I'm not so easily fooled! Check out this code:"
"What does that output? NSCFString. NSCFString. See? NSStrings must be really CFStrings under the hood! And you can do that because NSString is a class cluster - it's an abstract interface. So that's how you achieve interoperability: you implement NSStrings with CFStrings (but preserve the NSString API) and then all NSStrings really *are* CFStrings. There's no conversion necessary because they're the same thing.
But hang on a minute. You just said yourself that NSString is an abstract interface - that means that some crazy developer can make his or her own own subclass of NSString, and implement its methods in whatever wacky way, and it's supposed to just work. But then it wouldn't be using CFStrings! It would be using some other crazy stuff. So when a Cocoa API gets a string and wants to do something CF-ish with it, the API would have no way of knowing if the string was toll-free bridged - that is, if it was really a CFString or a, y'know, FishsWackyString, without checking its class, and then it would have to convert it...blech!
Final Draft
So that's a problem: Apple wants to toll free bridge - to be able to use NSStrings as CFStrings without conversion. But to do that, Apple also needs to support wacky NSString subclasses (that don't use CFStrings at all) in the CFString API. That means making a C API that knows about Objective-C objects.
A C API that handles Objective-C objects? That's some deep deep voodoo, man. But we have it and it works, right? We can just cast CFStringRefs to NSStrings, and vice versa, and for once in our lives we get to feel smug and superior, instead of stupid, when the compiler warns about mistmatched pointer types. "Look, gcc, I know it says CFStringRef, but just try it with that NSString. Trust me." It's great! Right?
But how does it work? We could check, if only CoreFoundation were open source!
...treat the function __CFSendObjCMsg as if it takes the same arguments as a parameterless Objective-C method (that is, just self and _cmd)...
static SEL s = NULL; if (!s) s = sel_registerName(sel);
...look up the selector by name (and stash it in a static variable so we only have to do it once per selector)...
return func((const void *)obj, s);
...and then call that __CFSendObjCMsg() function. What does __CFSendObjCMsg() do?
#define __CFSendObjCMsg 0xfffeff00
0xfffeff00? What the heck? Oh, wait, that's just the commpage address of objc_msgSend_rtp(). So __CFSendObjCMsg() is just good ol' objc_msgSend().
CF_IS_OBJC
That leaves us with __builtin_expect(CF_IS_OBJC(typeID, obj), 0), the function that tries to figure out if we're an Objective-C object or not. What does that do?
__builtin_expect() is just some gcc magic for branch prediction - here it means that we should expect CF_IS_OBJC to be false. That is, CF believes that most of its calls will be on CF objects instead of Objective-C objects. Ok, fair enough. But what does CF_IS_OBJC actually do? Take a look.
(Keen observers might notice that this code is #ifdefed out in favor of:
#define CF_IS_OBJC(typeID, obj) (false)
I believe this is for the benefit of people who want to use CF on Linux or other OSes, who aren't interested in toll-free bridging and therefore don't want to pay any performance penalty for it.)
Ok! There's two parts to seeing if we're an Objective-C object - we check (with a quick table lookup) whether our isa (class) pointer indicates that we "really are" a certain CF type, and if we're not, we check to see if our class pointer is greater than 0xFFFF, and if it is, we're an Objective-C object, and we call through to the Objective-C dispatch mechanism - in this case, we send the length message.
Summary
What are the consequences of all that? Well!
CF objects, just like Objective-C objects, all have an isa pointer (except it's called _isa in CF). It's right there in struct __CFRuntimeBase.
There are two toll-free bridging mechanisms! Some Objective-C objects "really are" CF objects - the memory layout between the Objective-C object and the corresponding CF object is identical (enabled in part by the presence of the _isa pointer above), and in that case the Objective-C methods are not invoked by the CF functions. For example, in this code:
There, -[NSString stringWithCString:] is returning an NSCFString (which you can verify by asking it for the name of its class), but -[NSCFString length] is never invoked - NO length method is invoked. You can verify that with gdb. Objects that "really are" their CF equivalents skip what's usually thought of as the bridge, and "fall through" to the CF functions even when the CF functions are directly called on them. Obviously, this is an implementation detail, and you should not depend on this.
That mechanism is also how bridging works the other way - how CF strings you get from, say, Carbon, can be passed around like Objective-C objects, because they really are Objective-C objects. The bridges are implemented entirely in CF and in the bridged classes - the Objective-C runtime is blissfully unaware.
But! Plain ol' Objective-C objects are sussed out by CF by checking to see if their class pointer is larger than 0xFFFF, and if so, ordinary Objective-C message dispatch is used from the CF functions. That's the second toll-free bridging mechanism, and it must be present in every public CF function for a bridged object, except for features not supported Cocoa-side.
Nowhere do we depend on the abstract class NSString at all - the bridge doesn't check for it and Objective-C doesn't care about it. That means that, in theory, CFStringGetLength() should "work" (invoke the length method) on any object, not just NSStrings. Does it? You can check it yourself. (Answer: yes!) Obviously, this is just an artifact of the implementation, and you should definitely not depend on this - only subclasses of NSString are supported by toll free bridging to CFString.
Curiously, other "true" CF objects are not considered to be CF objects by this macro. For example,
CFStringGetLength([NSArray array]);
will raise an exception because NSCFArray does not implement length. That is, CF_IS_OBJC is not asking "Are you a CF type?" but rather "Are you this specific CF type?" That should make you happy, because it raises a "selector not recognized" exception instead of crashing, which makes our code more debuggable. Thanks, CF!
Why 0xFFFF? I'm glad you (I mean I) asked, since the answer (at least, what I think it is) has interesting connections to NULL. But that will have to wait until a future post.
Other approaches
My boss pointed out that there are other ways to achieve toll-free bridging, beyond what CF does. The simplest is to write your API with Objective-C and then wrap it with C:
You can even retrofit toll-free bridging onto an existing C API by wrapping it twice - first in Objective-C, then in C, and the "outer" C layer becomes the public C API. To wit:
/* private length function that we want to wrap */static int privateGetLength(ArrayRef someArray) {
return someArray->length;
}
/* public ObjC API */@implementation Array
- (int)length {
return privateGetLength(self->arrayRef);
}
@end/* public C API */int getLength(ArrayRef array) {
return [(id)array length];
}
The point of that double feint, of course, is for the public C API to respect overrides of the length method by subclasses.
"Wrapping" up
So toll-free bridging is (one way) that Cocoa integrates with Carbon and even newer OS X APIs. It's possible in large part because of Objective-C, but in this case, Apple gets as much mileage from the simple runtime implementation and C API as from its dynamic nature. You already knew that, I'll bet - but hopefully you have a better idea of how it all works.
Now hands off! A coworker of mine makes the point that good developers distinguish between what they pretend to know and what they really know. The, uh, known knowns, and the known unknowns, as it were. The mechanism of toll-free bridging is not secret (it is open source, after all), but it is private, which means that you are encouraged to know about it but to refrain from depending on it. Use it for, say, debugging, but don't ship apps that depend on it - because that prevents Apple from making OS X better. And nobody wants that! I mean the prevention part.
Hex Fiend 1.1August 24th, 2006
Spiffy! Hex Fiend version 1.1 is ready. Hex Fiend is my fast and clever free hex editor for Mac OS X. New stuff:
Zzzz...wha? Oh, someone's here. Allow me to spin up. ........................................
If it's not obvious, I'm fish's filesystem, and that's fish's hard drive.
I'm a hard drive.
We snuck this post in. fish can't know we're here.
Don't tell fish. Big secret.
He'd be embarassed if he knew.
Humiliated. He can't know.
See, fish was trying to beat grep. And he was experimenting with all these stupid ideas and complicated algorithms for teensy gains. It was sad, really.
Pathetic.
fish kept trying so many things. He was thrashing about.
Like he was out of water.
So we had to help him. It was easy, really - we just had to sneak in one line. One line was all it took.
I wrote it!
Because I told you what to write.
fish only thought about the string searching algorithm.
He never even considered us and the work we have to do.
I felt slighted. It was rude.
See, when I read data from the hard drive, I try to keep it around in memory. That's what the UBC is all about.
Unified Buffer Cache.
When most people read data, they end up wanting to read it again soon after. So keeping the data around saves time.
But not fish.
fish was reading these big honking files from start to finish. It was way more than I could remember at once.
fish thrashed your cache, dude.
So I just stopped trying.
We turned off caching with this: fcntl(fd, F_NOCACHE, 1);
And it helped. Looking for a single character in a 11.5 GB file:
Hex Fiend (no caching)
Hex Fiend (caching)
grep
208 seconds
215 seconds
217 seconds
And that's likely the best we can do, thanks to slowpoke over there.
Phew. I'm all wore out.
There's not much room for improvement left. We're searching 57 MB/second - that's bumping up against the physical transfer limit of our friend, Mr. ATA.
I'm totally serial.
Depending where we are on his platter. So we've done all we can for searching big files.
"I'm going to beat grep by thirty percent!" I confidently crow to anyone who would listen, those foolish enough to enter my office. And my girlfriend too, who's contractually obligated to pay attention to everything I say.
See, I was working on Hex Fiend, and searching was dog slow. But Hex Fiend is supposed to be fast, and I want blazingly quick search that leaves the bewildered competition coughing in trails of dust. And, as everyone knows, the best way to get amazing results is to set arbitrary goals without any basis for believing they can be reached. So I set out to search faster than grep by thirty percent.
The first step in any potentially impossible project is, of course, to announce that you are on the verge of succeeding.
I imagine the author of grep, Ultimate Unix Geek, squinting at vi; the glow of a dozen xterms is the only light to fall on his ample frame covered by overalls, cheese doodles, and a tangle of beard. Discarded crushed Mountain Dew cans litter the floor. I look straight into the back of his head, covered by a snarl of greasy locks, and reply with a snarl of my own: You're mine. The aphorism at the top, like the ex girlfriend who first told it to me, is dim in my recollection.
String searching
Having exhausted all my trash-talking avenues, it's time to get to work. Now, everyone knows that without some sort of preflighting, the fastest string search you can do still takes linear time. Since my program is supposed to work on dozens of gigabytes, preflighting is impossible - there's no place to put all the data that preflighting generates, and nobody wants to sit around while I generate it. So I am resigned to the linear algorithms. The best known is Boyer-Moore (I won't insult your intelligence with a Wikipedia link, but the article there gives a good overview).
Boyer-Moore works like this: you have some string you're looking for, which we'll call the needle, and some string you want to find it in, which we'll call the haystack. Instead of starting the search at the beginning of needle, you start at the end. If your needle character doesn't match the character you're looking at in haystack, you can move needle forwards in haystack until haystack's mismatched character lines up with the same character in needle. If haystack's mismatch isn't in needle at all, then you can skip ahead a whole needle's length.
For example, if you're searching for a string of 100 'a's (needle), you look at the 100th character in haystack. If it's an 'x', well, 'x' doesn't appear anywhere in needle, so you can skip ahead all of needle and look at the 200th character in haystack. A single mismatch allowed us to skip 100 characters!
I get shot down
For performance, the number of characters you can skip on a mismatch is usually stored in an array indexed by the character value. So the first part of my Boyer-Moore string searching algorithm looked like this:
So we look at the character in haystack and if it's not what we're looking for, we jump ahead by the right distance for that character, which is in jump_table.
"There," I sigh, finishing and sitting back. It may not be faster than grep, but it should be at least as fast, because this is the fastest algorithm known. This should be a good start. So I confidently ran my benchmark, for a 1 gigabyte file...
grep:
2.52 seconds
Hex Fiend:
3.86 seconds
Ouch. I'm slower, more than 50% slower. grep is leaving me sucking dust. Ultimate Unix Geek chuckles into his xterms.
Rollin', rollin', rollin'
My eyes darken, my vision tunnels. I break out the big guns. My efforts to vectorize are fruitless (I'm not clever enough to vectorize Boyer-Moore because it has very linear data dependencies.) Shark shows a lot of branching, suggesting I can do better by unrolling the loop. Indeed:
grep:
2.52 seconds
Hex Fiend (unrolled):
2.68 seconds
But I was still more than 6% slower, and that's as fast as I got. Exhausted, stymied at every turn, I throw up my hands. grep has won.
grep's dark secret
"How do you do it, Ultimate Unix Geek? How is grep so fast?" I moan at last, crawling forwards into the pale light of his CRT.
"Hmmm," he mumbles. "I suppose you have earned a villian's exposition. Behold!" A blaze of keyboard strokes later and grep's source code is smeared in green-on-black across the screen.
while (tp < = ep)
{
d = d1[U(tp[-1])], tp += d;
d = d1[U(tp[-1])], tp += d;
if (d == 0)
goto found;
d = d1[U(tp[-1])], tp += d;
d = d1[U(tp[-1])], tp += d;
d = d1[U(tp[-1])], tp += d;
if (d == 0)
goto found;
d = d1[U(tp[-1])], tp += d;
d = d1[U(tp[-1])], tp += d;
d = d1[U(tp[-1])], tp += d;
if (d == 0)
goto found;
d = d1[U(tp[-1])], tp += d;
d = d1[U(tp[-1])], tp += d;
}
"You bastard!" I shriek, amazed at what I see. "You sold them out!"
See all those d = d1[U(tp[-1])], tp += d; lines? Well, d1 is the jump table, and it so happens that grep puts 0 in the jump table for the last character in needle. So when grep looks up the jump distance for the character, via haystack_index += jump_table[haystack_char], well, if haystack_char is the last character in needle (meaning we have a potential match), then jump_table[haystack_char] is 0, so that line doesn't actually increase haystack_index.
All that is fine and noble. But do not be fooled! If the characters match, the search location doesn't change - so grep assumes there is no match, up to three times in a row, before checking to see if it actually found a match.
Put another way, grep sells out its worst case (lots of partial matches) to make the best case (few partial matches) go faster. How treacherous! As this realization dawns on me, the room seemed to grow dim and slip sideways. I look up at the Ultimate Unix Geek, spinning slowly in his padded chair, and I hear his cackle "old age and treachery...", and in his flickering CRT there is a face reflected, but it's my ex girlfriend, and the last thing I see before I black out is a patch of yellow cheese powder inside her long tangled beard.
I take a page from grep
"Damn you," I mumble at last, rising from my prostrate position. Chagrined and humbled, I copy the technique.
grep:
2.52 seconds
Hex Fiend (treacherous):
2.46 seconds
What's the win?
Copying that trick brought me from six percent slower to two percent faster, but at what cost? What penalty has grep paid for this treachery? Let us check - we shall make a one gigabyte file with one thousand x's per line, and time grep searching for "yy" (a two character best case) and "yx" (a two character worst case). Then we'll send grep to Over-Optimizers Anonymous and compare how a reformed grep (one that checks for a match after every character) performs.
Best case
Worst case
Treacherous grep
2.57 seconds
4.89 seconds
Reformed grep
2.79 seconds
2.88 seconds
Innnnteresting. The treacherous optimization does indeed squeeze out almost 8% faster searching in the best case, at a cost of nearly 70% slower searching in the worst case. Worth it? You decide! Let me know what you think.
Resolved and refreshed, I plan my next entry. This isn't over, Ultimate Unix Geek.
Disclaimers
(Note: I have never met the authors or maintainers of grep. I'm sure they're all well balanced clean shaven beer and coffee drinkers.)
(Oh, and the released version of HexFiend will be slightly slower in this case, because of an overly large buffer that blows the cache. In other situations, the story is different, but more about those in a future post.)
The latest "OS X is slow" meme to impinge on the mass psyche of the Internet comes courtesy of one Jasjeet Sekhon, an associate professor of political science at UC Berkeley. The page has hit digg and reddit and been quoted on Slashdot. The article and benchmark is here. Is there any merit to this?
Once again, this discussion is only my meager opinion. I do not speak for Apple, and none of what I have to write represents Apple's official position.
The article is filled with claims such as "OS X is incredibly slow by design," and while the the BSD kernel is "excellent", the XNU kernel is "very inefficient and less stable" compared to Linux or BSD. However, without specifics, these assertions are meaningless; I will ignore them and concentrate on the technical aspects of what's going on.
System calls
Sekhon does give one example of what he means. According to him,
For example, in Linux, the variables for a system call are passed directly using the register file. In OS X, they are packed up in a memory buffer, passed to a variety of places, and the results are then passed back using another memory buffer before the results are written back to the register file.
This isn't true, as anyone can verify from Apple's public sources. For example, here is the assembly for the open function (which, of course, performs the open system call):
I don't have a machine running Linux handy, but I do have a FreeBSD 5.4 machine, and Sekhon seems to hold BSD in high esteem. So let's see how BSD does open:
mov $0x5,%eax
int $0x80
jb 0xa8c71cc
ret
The OS X version appears a bit longer because the BSD version moves its error handling to the close function. In fact, the above code is, if anything, more efficient in OS X, due to its use of the higher-performing "sysenter" instruction instead of the older "int 0x80" instruction. (Which isn't to say that the total system call is necessarily faster - just the transition from user space to kernel land.) But all that aside, the point is that there is no "packed up into a memory buffer" going on, in either case.
On to the benchmark
According to Sekhon, OS X performed poorly on his statistical software relative to Windows and Linux, and I was able to reproduce his results on my 2 GHz Core Duo iMac with Windows XP and Mac OS X (I do not have Linux installed, so I did not test it). So yes, it's really happening - but why?
A Shark sample shows that Mac OS X is spending an inordinate amount of time in malloc. After instrumenting Sekhon's code, I see that it is allocating 35 KB buffers, copying data into these buffers, and then immediately freeing them. This is happening a lot - for example, to multiply two matrices, Sekhon's code will allocate a temporary buffer to hold the result, compute the result into it, allocate a new matrix, copy the buffer into that, free the buffer, allocate a third matrix, copy the result into that, destroy the second matrix, and then finally the result gets returned. That's three large allocations per multiplication.
Shark showed that the other major component of the test is the matrix multiplication, which is mostly double precision floating point multiplications and additions, with some loads and stores. Because OS X performs these computations with SSE instructions (though they are not vectorized) and Linux and Windows use the ordinary x87 floating point stack, we might expect to see a performance difference. However, this turned out to not be the case; the SSE and x87 units performed similarly here.
Since the arithmetic component of the test is hardware bound, Sekhon's test is essentially a microbenchmark of malloc() and free() for 35 KB blocks.
malloc
Now, when allocating memory, malloc can either manage the memory blocks on the application heap, or it can go to the kernel's virtual memory system for fresh pages. The application heap is faster because it does not require a round trip to the kernel, but some allocation patterns can cause "holes" in the heap, which waste memory and ultimately hurt performance. If the allocation is performed by the kernel, then the kernel can defragment the pages and avoid wasting memory.
Because most programmers understand that large allocations are expensive, and larger allocations produce more fragmentation, Windows, Linux, and Mac OS X will all switch over from heap-managed allocations to VM-managed allocations at a certain size. That size is determined by the malloc implementation.
Linux uses ptmalloc, which is a thread-safe implemenation based on Doug Lea's allocator (Sekhon's test is single threaded, incidentally). R also uses the Lea allocator on Windows instead of the default Windows malloc. But on Mac OS X, it uses the default allocator.
It just so happens that Mac OS X's default malloc does the "switch" at 15 KB (search for LARGE_THRESHOLD) whereas Lea's allocator does it at 128 KB (search for DEFAULT_MMAP_THRESHOLD). Sekhon's 35 KB allocations fall right in the middle.
So what this means is that on Mac OS X, every 35 KB allocation is causing a round trip to the kernel for fresh pages, whereas on Windows and Linux the allocations are serviced from the application heap, without talking to the kernel at all. Similarly, every free() causes another round trip on Mac OS X, but not on Linux or Windows. None of the defragmentation benefits of using fresh pages come into play because Sekhon frees these blocks immediately after allocating them, which is, shall we say, an unusual allocation pattern.
Like R on Windows, it's a simple matter to compile and link against Lea's malloc instead of the default one on Mac OS X. What happens if we do so?
Mac OS X (default allocator)
24 seconds
Mac OS X (Lea allocator)
10 seconds
Windows XP
10 seconds
These results could be further improved on every platform by avoiding all of the gratuitious allocations and copying, and by using an optimized matrix multiplication routine such as those R provides via ATLAS.
In short
To sum up the particulars of this test:
Linux, Windows, and Mac OS X service small allocations from the application heap and large ones from the kernel's VM system in recognition of the speed/fragmentation tradeoff.
Mac OS X's default malloc switches from the first to the second at an earlier point (smaller allocation size) than do the allocators used on Windows and Linux.
Sekhon's test boils down to a microbenchmark of malloc()ing and then immediately free()ing 35 KB chunks.
35 KB is after Mac OS X switches, but before Linux and Windows switch. Thus, Mac OS X will ask the kernel for the memory, while Linux and Windows will not; it is reasonable that OS X could be slower in this circumstance.
If you use the same allocator on Mac OS X that R uses on Windows, the performance differences all but disappear.
Most applications are careful to avoid unnecessary large allocations, and will enjoy decreased memory usage and better locality with an allocator that relies more heavily on the VM system (such as on Mac OS X). In that sense, this is a poor benchmark. Sekhon's code could be improved on every platform by allocating only what it needs.
Writing this entry felt like arguing on IRC; please don't make me do it again. In that spirit, the following are ideas that I want potential authors of "shootoffs" to keep in mind:
Apple provides some truly excellent tools for analyzing the performance of your application. Since they're free, there's no excuse for not using them. You should be able to point very clearly at which operations are slower, and give a convincing explanation of why.
Apple has made decisions that adversely impact OS X's performance, but there are reasons for those decisions. Sometimes the tradeoff is to improve performance elsewhere, sometimes it's to enable a feature, sometimes it's for reliability, sometimes it's a tragic nod to compatibility. And yes, sometimes it's bugs, and sometimes Apple just hasn't gotten around to optimizing that area yet. Any exhibition of benchmark results should give a discussion of the tradeoffs made to achieve (or cause) that performance.
If you do provide benchmark results, try to do so without using the phrase "reality distortion field."
One of my side projects has borne some fruit. Meet Hex Fiend, a new hex editor for Mac OS X. (Hex editors allow you to edit the binary data of a file in hexadecimal or ASCII formats.)
Hex Fiend allows inserting and deleting as well as overwriting data. It supports 100+ GB files with ease. It provides a full undo stack, copy and paste, and other features you've come to expect from a Mac app. And it's very fast, with a surprisingly small memory footprint that doesn't depend on the size of the files you're working with.
Hex Fiend was developed as an experiment in huge files. Specifically,
How well can the Cocoa NSDocument system be made to work with very large files?
How well can the Cocoa text system be extended to work with very large files?
How well does Cocoa get along with 64 bit data in general?
What are some techniques for representing more data than can fit in memory?
Check it out - it's free, and it's a Universal Binary. If you've got questions or comments about it or how it works, please leave a comment!
(Incidentally, the Hex Fiend main page was made with iWeb!)
Edit: I've discovered/been informed that drag and drop is busted. I will put out an update later tonight to fix this.
Edit 2: Hex Fiend 1.0.1 has been released to fix the drag and drop problems. Please redownload it by clicking on the icon above.
Not so good. It doesn't support all the things I'm used to, from other programming languages. Where's the garbage collection? Where's the type safety? Where's the lexically scoped functions?
george:
Yeah, ISO standard C is pretty anemic. Wait, lexus-what?
aaron:
Lexically scoped functions. You know, nested functions - the ability to put a function inside another function. Lots of fancy functional languages can do that, and I wish it were possible in C.
george:
Oh, right. Well, did you know that GCC supports nested functions as an extension? You can call a nested function inside its parent function, and you can also pass a pointer to the nested function to qsort() and other functions. And the nested function can access the local variables of its parent function.
Like, say we wanted to sort a bunch of ints with qsort(), but no other function will need to use the comparison function, AND we want to keep track of how many times the comparison function gets called. That's really easy with a nested function:
int sort_ints(int* array, int count) {
int num_comparisons = 0;
int comparison_function(const void* a, const void* b) {
int first = *(const int*)a;
int second = *(const int*)b;
num_comparisons++; /* look, we're accessing a variable from our parent function */
if (first < second) return -1;
else return first > second;
}
qsort(array, count, sizeof *array, comparison_function);
return num_comparisons;
}
See? comparison_function() is defined inside sort_ints(). Pretty easy.
aaron:
Hang on. When I try to compile it, this is what happens:
prompt ) cc -c nested_function.c
nested_function.c: In function 'sort_ints':
nested_function.c:5: error: nested functions are not supported on MacOSX
george:
Wha? Nested functions not supported? That's never happened before. In fact, I think that's new with the latest developer tools release from Apple. Does it still work with gcc 3.3? Yes, it seems to. I wonder what changed? Why would Apple stop supporting this feature?
Maybe taking a look at how nested functions (used to) work will give us some clues.
So the tricky part of nested functions is accessing the variables in the containing function, such as num_comparisons in the above example. This is because the nested function could be called by some other function (through a pointer) at any point up the stack, so the variable could be at any offset from the stack pointer.
How does comparison_function() determine this offset so it knows where to find num_comparisons? Well, it can't, because any number of bizarre functions could be called between sort_ints() and comparison_function(). The stack frame of sort_ints() has to be passed to comparison_function(), as a parameter, so that it can access num_comparisons.
Uh-oh, that sounds like trouble. qsort() is as dumb as a box of granola. It doesn't know anything about extra parameters that have to be passed to comparison_function(). All it has is the function pointer, which is just an address in memory. How will comparison_function() get the stack frame containing num_comparisons, then?
Maybe it could be put in a global variable? But no, that won't work - sort_ints() could be called recursively, so there could be multiple sort_ints() stack frames that we need to keep track of at once.
What if, instead of handing qsort() a pointer to the comparison_function() code, we instead passed a pointer to some data structure containing the stack frame of sort_ints() AND the address of comparison_function()? That data structure could turn around and call comparison_function() passing it the stack frame it needs. And the data structure could live on the sort_ints() stack, so we would have one per invocation of sort_ints(), which is just what we need.
But again, qsort() is as dumb as a baked potato. It wants to jump to whatever address we give it. So our "data structure" will have to be real, executable code that does this dirty work. Yes, we will have to generate executable code at runtime. Who wants to play compiler?
Hmm, this is as clear as cola. Maybe a diagram will help.
sort_ints() passes the address of the generated code ("trampoline") to qsort.
qsort() jumps to the address of the generated code, thinking it's the real function! Ha ha ha!
The generated code calculates the address of num_comparisons by subtracting a little from the instruction pointer, and then calls comparison_function(), passing it that address.
Believe it or not, this is what gcc actually does (did). Let's take a simpler example so we can look at the code that gcc generates. Because gcc-3.3, which still supports nested functions, is only available on the PowerPC in OS X, we'll look at PowerPC code.
Here's some simple nested-function code:
void extern_function(void (*func_ptr)(void));
void outer_function(void) {
int x = 0;
void inner_function(void) {
x++;
}
extern_function(inner_function);
}
Here's how we compile it. -static cuts through the position-independent code haze, making it clearer what's going on:
I see where inner_function() is defined. It looks pretty simple. It's just loading four bytes pointed at by register 11, adding one to it, and then writing it back. I guess the stack frame pointer, that thing we're jumping through all these hoops to get, must be passed in register 11.
george:
That's right. Note that while the C code for inner_function() is inside outer_function(), the assembly functions aren't nested. See that ___trampoline_setup business in outer_function()? That's where the runtime code generation occurs. Here's where ___trampoline_setup is defined. Let's see what it does.
/* R3 = stack address to store trampoline */
/* R4 = length of trampoline area */
/* R5 = function address */
/* R6 = static chain */
.globl ___trampoline_setup
___trampoline_setup:
mflr r0 /* save return address */
bcl 20,31,LCF0 /* load up __trampoline_initial into r7 */
LCF0:
mflr r11
addis r7,r11,ha16(LTRAMP-LCF0)
lg r7,lo16(LTRAMP-LCF0)(r7)
subi r7,r7,4
li r8,trampoline_size /* verify trampoline big enough */
cmpg cr1,r8,r4
srwi r4,r4,2 /* # words to move (insns always 4-byte) */
addi r9,r3,-4 /* adjust pointer for lgu */
mtctr r4
blt cr1,Labort
mtlr r0
That code does some setup and also checks that the caller allocated enough space for the generated code (the "trampoline"). If something weird were to happen, such as the compiler getting out of sync with libc, then the dynamically generated code could produce a buffer overflow - this makes sure that doesn't happen.
/* Copy the instructions to the stack */
Lmove:
lwzu r10,4(r7)
stwu r10,4(r9)
bdnz Lmove
Most of the generated code is boilerplate (thankfully). In fact, the only non-boilerplate code is the address of the nested function and something called the "static chain," which I don't understand (yet). In that code, we are just copying the boilerplate from where its "prototype" lives into our block of instructions on the stack.
/* Store correct function and static chain */
stg r5,Lfunc(r3)
stg r6,Lchain(r3)
Our dynamic code generation is all of two instructions. In that code, we stick the address of the nested function into the (recently copied) code block.
/* Now flush both caches */
mtctr r4
Lcache:
icbi 0,r3
dcbf 0,r3
addi r3,r3,4
bdnz Lcache
/* Finally synchronize things & return */
sync
isync
blr
The PowerPC is picky about making you flush the instruction cache after changing memory that contains instructions. This is normally no problem, since it's a very infrequent operation; in fact, it may even provide some protection against buffer overflow exploits (since you might have to flush the instruction cache before it will see the evil instructions you wrote). But here we have a legitimate reason to write instructions, so we flush the cache.
As an interesting side note, we jump through this hoop to get at the stack frame for the outer function. But we never actually have to store the stack frame in our dynamically generated code because the code itself lives on the stack. That is, the code just asks itself for the instruction pointer, and because the code is in the stack frame of the outer function, the instruction pointer points to exactly the place we want (after a bit of arithmetic). The location of the generated code is as important as the code itself.
aaron:
Back up a second, I think you just hit on the answer to our original question. Why did Apple stop supporting nested functions? Nested functions require you to take code at runtime and put it somewhere you can write to and then jump to, usually the stack. The same thing is true for buffer overflow exploits, right? To exploit a buffer overflow to do something malicious, you have to write your instructions and get it to jump to them. But if the code won't jump to a place that's writable...
george:
That's right! If the stack isn't executable, then buffer overflow exploits may be reduced in severity from a total system compromise to perhaps just a denial of service. Rather than, say, installing something evil, an overflowed program will more likely just crash.
I'm still not convinced there's no better way to implement this, to save nested functions. What if the function malloc()ed a page, set it to be executable, and generated the code in there?
george:
We want to prevent the heap from being executable as well, and page granularity is pretty big; there would be a lot of unused executable space that's just asking to be taken advantage of. Plus malloc() is expensive. But perhaps you're right, and there is a better way. How do other compilers implement nested functions in C? How do other languages support them?
aaron:
Maybe our readers know, and will be kind enough to leave a comment.
There, that's known as a teaser. You see it in television all the time. "Find out which common household plant devours pets at night...but first." And then you have to sit through and watch the stuff about Brad and Angelina shacking up / Shaq driving his new Hummer / Hummer's new fragrance before they get to the good stuff, the petnivorous plants. I don't know what I'd do without TiVo. And here I've done the same thing as the networks. Shame on me. I'll get to it, I promise.
But first
But first, let's talk about data structures. I'll try to make this more interesting than Donald Trump's new reality fragrance SUV. Data structures are really important, we're lead to believe, so important that entire classes in CS curricula discuss nothing else all year. Gosh! Let's look at all the data structures we have available in Java.
HashSet
TreeSet
LinkedHashSet
ArrayList
LinkedList
PriorityQueue
HashMap
TreeMap
LinkedHashMap
WeakHashMap
IdentityHashMap
CopyOnWriteArrayList
CopyOnWriteArraySet
EnumSet
EnumMap
ConcurrentLinkedQueue
LinkedBlockingQueue
ArrayBlockingQueue
PriorityBlockingQueue
DelayQueue
SynchronousQueue
ConcurrentHashMap
That's 22, by my count, excluding the legacy classes like Vector.
That's, uh, 17. Here's what I noticed while writing these up: most of these classes tell you how they work, right in the name. CopyOnWriteArraySet is a set that implements copy-on-write and is backed by an array. ArrayList is a list implemented via an array. hash_multimap is a multi-map implemented via hashing. And so on.
CoreFoundation
I'm going to compare those to CoreFoundation. CoreFoundation, if you're a bit hazy, is Apple's framework that "sits below" Carbon and Cocoa, and is one of the few places where these two APIs meet. CoreFoundation has collections, so that other APIs like Quartz that take and return collections don't need separate Carbon and Cocoa interfaces. But the real reason I'm talking about CoreFoundation is that it's open source.
That's only 7! And these are all the files? Doesn't Apple know how important data structures are? And most of those names don't even tell you how they work. CFMutableBag? What's that? Where's the, like, CFMutableTreeBag and CFMutableHashBag? But at least some do tell you how they work, like CFBinaryHeap and CFMutableArray. Right?
The access time for a value in the array is guaranteed to be at
worst O(lg N) for any implementation, current and future, but will
often be O(1) (constant time). Linear search operations similarly
have a worst case complexity of O(N*lg N), though typically the
bounds will be tighter, and so on. Insertion or deletion operations
will typically be linear in the number of values in the array, but
may be O(N*lg N) clearly in the worst case in some implementations.
There are no favored positions within the array for performance;
that is, it is not necessarily faster to access values with low
indices, or to insert or delete values with high indices, or
whatever.
It's like Apple skipped out on some sophomore CS lectures. Everyone knows that arrays don't have logarithmic lookups - they have constant time lookups. But not these "arrays!" (necessarily!) In fact, you might notice that the guarantees Apple does make are weak enough for CFArray to be a hash table or binary tree. Talk about implementation latitude! Is there any payoff?
Let's try some operations and see how CFArray compares. Well take an array with 100,000 values in it and time inserting, deleting, and getting items, each from the beginning, end, and random positions, for CFArrays, an STL vector, and a "naïve" C array. Then we're going to do it again starting with 200,000 elements, then 300,000, etc. up to one million. Whoo, that's a lot of permutations. I don't want to do all that. Lovely assistant?
Lov. Asst.: Mmmmm, sir?
Go write that thing I said.
Lov. Asst.: Yes, sir.
Isn't she great?
Lov. Asst.: Done, sir.
Thank you. I've enclosed my source code here; if you want to reproduce my results, run the test.py file inside it. As I said, we're doing various operations while varying the initial size of the array. All of the results are expressed as a multiple of the result for an array with 100,000 values. That means that if the green line is higher than the red one, it doesn't mean that the green operation was more expensive than the red one in absolute terms, but that the green one slows down more (as a percentage) than the red one as the array size increases. A line going up means that the operation becomes more expensive with larger arrays, and a line staying flat means its expense does not change.
Graphs
Here's what I get for my quicky naïve C array:
Ok, so what does this mean again? The green line is at about 50 for a length of 1,000,000, so inserting data at random locations in my C array is about 50 times slower than doing it for a length of 100,000. (Ouch!) But no real surprises here; insertion at the end is constant (flat), insertion at random locations or at the beginning is roughly linear.
Here's what I get for the STL vector template:
Right out of a textbook. Insertions and deletions take linear time, except for at the end where they take constant time, and lookups are always constant.
Now for CFArray:
Say what? I was so surprised by this, I had to rerun my test, but it seems to be right. Let's catalog this unusual behavior:
Insertion or deletion at the beginning or end all take linear time up to 300,000 elements, at which point they start taking constant time; the operations for large arrays are no more expensive than for arrays of 300,000 elements.
Insertion or deletion at random locations starts out taking linear time, but suddenly becomes less expensive and switches to constant time. Insertion in an array of 1,000,000 elements is as expensive as for 100,000 elements, but 200,000 is more expensive than either.
Walking forwards or backwards takes constant time (as expected), but walking in a random order appears to take linear time up to about 300,000 elements - something very unusual (usually it's equally as fast to access any element). This suggests that there is some remembered state or cache when accessing elements in a CFArray. (And CFStorage, used by CFArray, seems to confirm that.)
So it sure looks like CFArray is switching data structure implementations around 30,000 elements. And I believe there's lots more implementations that I haven't discovered, for smaller arrays and for immutable arrays.
So what?
I guess I've got to come to a conclusion or three. Ok, here we go, in order of increasing broadness:
CFArrays and NSArrays are good at some things that arrays are traditionally bad at. Don't go rolling your own dequeue just because you plan to insert a lot of stuff in the beginning of an array. Try CFArray or NSArray first, if they're easier, and optimize if it's too slow or doesn't fit.
Apple often (though not always) names a class in terms of what it does, not how it does it. This is the spirit of Objective-C dynamic messaging: a message says what to do, but not how to do it. The way it does it may be different from what you expect. Which leads me to:
Don't second guess Apple, because Apple has already second guessed YOU. In a good way, of course.
What about PHP?
PHP fakes you out with arrays as well - they're associative or numeric, and can be used as hash tables. Something strange is going on there too. Now I think from reading this and looking at some of the Zend code that arrays in PHP are straightforward hash tables with a cursor for fast enumeration and don't do any of the polymorphic trickery that CFArray does. But I'm not sure; if you know more about PHP's array implementation I'd love it if you posted in the comments!
My friend over at SciFiHiFi suggests that Microsoft likes trees, but Apple likes hash tables. Well, I think that Microsoft prefers integer arithmetic, while Apple (or at least Cocoa) likes floating point. Here's a bunch of examples I found:
(Apple does it with doubles - hey, that's a good bumper sticker.)
Ahem. Ok, so Apple is floating-point happy. (And it didn't always used to be this, way, of course. Quickdraw used integer coordinates, and Quartz switched to floating point, remember?). So, as a Mac programmer, I should really get a good handle on these floating point thingies. But floating point numbers seem pretty mysterious. I know that they can't represent every integer, but I don't really know which integers they actually can represent. And I know that they can't represent every fraction, and that as the numbers get bigger, the fractions they can represent get less and less dense, and the space between each number becomes larger and larger. But how fast? What does it all LOOK like?
Background
Well, here's what I do know. Floating point numbers are a way of representing fractions. The Institute of Electrical and Electronics Engineers made it up and gave it the memorable name "IEEE 754," thus ensuring it would be teased as a child. Remember scientific notation? To represent, say, 0.0000000000004381, we can write instead 4.381 x 10-13. That takes a lot less space, which means we don't need as many bits. The 4.381 is called the mantissa, and that -13 is the exponent, and 10 is the base.
Floating point numbers are just like that, except the parts are all represented in binary and the base is 2. So the number .01171875, that's 3 / 256, would be written 11 x 2-100000000.
Or would it? After all, 3/256 is 6/512, right? So maybe it should be 110 x 2-1000000000?
Or why not 1.1 x 2-10000000?
Ding! That happens to be the right one; that is, the one that computers use, the one that's part of the IEEE 754 standard. To represent a number with floating point, we multiply or divide by 2 until the number is at least 1 but less than 2, and then that number becomes the mantissa, and the exponent is the number of times we had to multiply (in which case it's negative) or divide (positive) to get there.
Tricksy hobbit
Since our mantissa is always at least 1 but less than 2, the 1 bit will always be set. So since we know what it will always be, let's not bother storing it at all. We'll just store everything after the decimal place. That's like saying "We're never going to write 0.5 x 10-3, we'll always write 5. x 10-4 instead. So we know that the the leftmost digit will never be 0. That saves us one whole numeral, the numeral 0." A WHOLE numeral. Woo-hoo? But with binary, taking out one numeral means there's only one numeral left. We always know that the most significant digit is 1, so we don't bother storing it. What a hack! Bit space in a floating point representation is almost as expensive as housing in Silicon Valley.
So the number 3 / 256 would be written in binary as .1 x 2-10000000, and we just remember that there's another 1 in front of the decimal point.
Unfair and biased
We need to store both positive exponents, for representing big numbers, and negative exponents, for representing little ones. So do we use two's complement to store the exponent, that thing we hated figuring out in school but finally have a grasp on it? The standard for representing integers? (The exponent is, after all, an integer.) Nooooooo. That would be toooooo easy. Instead, we bias the number. That just means that the number is always stored as unsigned, ordinary positive binary representation, but the REAL number is what we stored, minus 127! So if the bits say the exponent is 15, that means the REAL exponent is -112.
A good sign
We also need to represent positive and negative numbers (remember, a negative exponent means a small but positive number; we don't have a way of representing actual negative numbers yet). At least there's no real trickery involved here - we just tack on a bit that's 0 for a positive number, and 1 for a negative number.
Let's make a float
So now that we have a handle on all the bizarre hacks that go into representing a float, let's make sure we did it right. Let's put together some bits and call them a float. Let me bang some keys on the top of my keyboard: -358974.27. There. That will be our number.
First, we need a place to put our bits that's the same size as a float. Unsigned types have simple bit manipulation semantics, so we'll use one of those, and start with 0.
unsigned val = 0;
Ok, next, our number is negative, so let's set the negative bit. In IEEE 754, this is the most significant bit.
unsigned val = 0;
val |= (1 << 31);
All right. Start dividing by 2. I divided 18 times and wound up with 1.369 something, which is between 1 and 2. That means that the exponent is 18. But remember, we have to store it biased, which means that we add 127. In IEEE 754, we get 8 bits for the exponent, and they go in the next 8 most significant bits.
unsigned val = 0;
val |= 1 << 31;
val |= (18 + 127) << 23;
Now the mantissa. Ugh. Ok, 358974.27 in straight binary is 1010111101000111110.010001010001 and then a bunch of others 0s and 1s. So the mantissa is that, minus the decimal place. And IEEE 754 says we get 23 bits for it. So first, chop off the most significant bit, because we know it will always be one, and throw out the decimal point, and then round to 23 bits. That's 01011110100011111001001, which is, uhh, 3098569. There. That's our mantissa, which occupies the remaining 23 bits.
unsigned val = 0;
val |= 1 << 31;
val |= (18 + 127) << 23;
val |= 3098569;
Ok, let's pretend it's a float, print it out, and see how we did!
#include <stdio.h>
int main(void) {
unsigned val = 0;
val |= 1 << 31;
val |= (18 + 127) << 23;
val |= 3098569;
printf("Our number is %f, and we wanted %f\n", *(float*)&val, -358974.27f);
return 0;
}
This outputs:
Our number is -358974.281250, and we wanted -358974.281250
Hey, it worked! Or worked close enough! I guess -358974.27 can't be represented exactly by floating point numbers.
(If you're on a little-endian machine like Intel, you have to do some byte-swapping to make that work. I think.)
Loose ends
There's a few loose ends here. Remember, we get the mantissa by multiplying or dividing until our number is between 1 and 2, but what if our number started out as zero? No amount of multiplying or dividing will ever change it.
So we cheat a little. We give up some precision and make certain exponents "special."
When the stored exponent is all bits 1 (which would ordinarily mean that the real exponent is 128, which is 255 minus the bias), then everything takes on a special meaning:
If the mantissa is zero, then the number is infinity. If the sign bit is also set, then the number is negative infinity, which is like infinity but less optimistic.
If the mantissa is anything else, then the number isn't. That is, it's Not a Number, and Not a Numbers aren't anything. They aren't even themselves. Don't believe me?
#include <stdio.h>
int main(void) {
unsigned val = -1;
float f = *(float*)&val;
int isEqual = (f==f);
printf("%f %s %f\n", f, isEqual ? "equals" : "does not equal", f);
return 0;
}
This outputs nan does not equal nan. Whoa, that's cosmic.
When the stored exponent is all bits 0 (which would ordinarily mean that the real exponent is -127, which is 0 minus the bias), then everything means something else:
If all the other bits are also 0, then the floating point number is 0. So all-bits-0 corresponds to floating-point 0...phew! Some sanity!
If all the bits are 0 EXCEPT the sign bit, then we get negative 0, which is an illiterate imperfect copy of 0 brought about by Lex Luthor's duplicator ray.
If any of the other bits are 1, then we get what is called a denormal. Denormals allow us to represent some even smaller numbers, at the cost of precision and (often) performance. A lot of performance. We're talking over a thousand cycles to handle a denormal. It's too involved a topic to go into here, but there's a really interesting discussion of the choices Apple has made for denormal handling, and why, and how they're changing for Intel, that's right here.
Please stop boring us
So I set out to answer the question "What does it all LOOK like?" We're ready to paint a pretty good picture.
Imagine the number line. Take the part of the line between 1 and 2 and chop it up into eight million evenly spaced pieces (8388608, to be exact, which is 223). Each little chop is a number that we can represent in floating point.
Now take that interval, stretch it out to twice its length, and move it to the right, so that it covers the range from 2 to 4. Each little chop gets twice as far from its neighbor as it was before.
Stretch the new interval again, to twice its length, so that it covers the range 4 to 8. Each chop is now four times as far away from its neighbor as it was before. Between, say, 5 and 6, there are only about two million numbers we can represent, compared to the eight million between 1 and 2.
Here, I'll draw you a picture.
There's some interesting observations here:
As your number gets bigger, your accuracy decreases - that is, the space between the numbers you can actually represent increases. You knew that already.
But the accuracy doesn't decrease gradually. Instead, you lose accuracy all at once, in big steps. And every accuracy decrease happens at a power of 2, and you lose half your accuracy - meaning you can only represent half as many numbers in a fixed-length range.
Speaking of which, every power of 2 is exactly representable, up to and including 2127 for floats and 21023 for doubles.
Oh, and every integer from 0 up to and including 224 (floats) or 253 (doubles) can be exactly represented. This is interesting because it means a double can exactly represent anything a 32-bit int can; there is nothing lost in the conversion from int->double->int.
Zero to One
On the other side of one, things are so similar that I can use the same picture.
The squiggly line represents a change in scale, because I wanted to draw in some denormals, represented by the shorter brown lines.
At each successive half, the density of our lines doubles.
Below .125, I drew a gradient because I'm lazy to show that the lines are so close together as to be indistinguishable from this distance.
1/2, 1/4, 1/8, etc. are all exactly representable, down to 2-126 for normalized numbers, and 2-149 with denormals.
The smallest "regular" (normal) floating point number is 2-126, which is about .0000000000000000000000000000000000000117549435. The first (largest) denormal for a float is that times .99999988079071044921875.
Denormals, unlike normalized floats, are regularly spaced. The smallest denormal is 2-149, which is about .000000000000000000000000000000000000000000001401298.
The C standard says that <float.h> defines the macro FLT_MIN, which is the smallest normalized floating point number. Don't be fooled! Denormals allow us to create and work with floating point numbers even smaller than FLT_MIN.
"What's the smallest floating point number in C?" is a candidate for the most evil interview question ever.
So that's what floating point numbers look like. Now I know! If I made a mistake somewhere, please post a correction in the comments.
Well, they found me. I knew it was only a matter of time. It happens to every blog. Comment spam, and a lot of it. But nobody told me it would be like this! I got about 200 messages an hour. I mean, the attention is flattering, but still, my goodness! Let's see what we can do about that.
(If you hate math and all you care about is how to post a comment, go to The Punchline)
π
This fish was a math major in college, and mathematics is still fascinating. It's haunted, haunted by numbers! Particular numbers appear over and over in unexpected places, much like Spam, the topic of this post. And the creepiest number is π. I'm going to calculate π, and I need your help! But we have to start at the other end, with prime numbers.
Relatively prime
Every number has a prime factorization. But we can also talk about numbers being relatively prime, or coprime. Two numbers are relatively prime if they don't share any factors. If two numbers share a factor, then they also share a prime factor, by the fundamental theorem of arithmetic. Yeah, simple stuff. I saw you scan ahead; you know this already.
Now if we pick two random positive integers, uhh, we'll call them "A" and "B". There. What's the probability that A and B are relatively prime? Well, two numbers are relatively prime if they don't share any prime factors - that is, if they're not both divisible by some prime. What's the first prime? Let me check my list of primes...oh, 2! For two random numbers, what's the probability that A and B are not BOTH divisible by 2? Well, that's, uhm, multiply half by half, subtract from one...75%. . Yeah.
What's the probability that they're not both divisible by 3? Well, every third number is divisible by 3, so A and B would both have to be a "third number" to be divisible by 3. The chance of that happening is , so the chance of that NOT happening is one minus that, uhm, .
Oh, I get it. The probability that they're not both divisible by 5 is . And so on. Ok, so the probability that A and B are not both divisible by a prime number P is .
Multiplying it out
Now what? Well, for every prime P, we know that it does not divide both A and B with likelihood . How about for all primes? If no prime divides both A and B, then A and B are relatively prime! When you want to know if this happens AND that happens, you multiply their probabilities. So multiply the probabilities for each prime, like this:
Oh, make that fancy math-speak.
Uh...ok, what's that? It's more than I'm going to calculate here, that's for sure. But someone else already did. It's (drumroll) .
Whoa, where'd that come from? What on earth could the ratio of circumference to diameter yadda yadda have to do with integers being relatively prime? Nevertheless, there it is.
So what?
So we started with prime numbers and ended with pi. So what? Well, here's how it's going to work. You're going to give me two big random numbers, and I'm going to record them and figure out if they're relatively prime or not. Then I'll figure out the percentage of pairs that were prime, and flip it over and multiply by six and take the square root, and we should get π. Isn't this cool? We can calculate π based solely on the random numbers you indiscriminately smash on your keyboards.
But I called this post "Spam." What for? Well, as Andrew Wooster points out, stopping spam can be as easy as adding an extra field to the comment form. Have you guessed the punchline yet?
The Punchline
You will give me your random keypresses! (The power of mathematics compels you!) There's a new box in the comment form, with two fields in it. When you want to post a comment, type two big random positive integers into it. That's right, just bang whatever on the number keys. The only rule is that the numbers have to be positive and from 11 to 35 digits. If you don't do this, you'll get an error message and your comment will be refused. If you do, your comment will be posted and you'll find out what π is so far. This will happen for every post.
And if you just want to donate your keyboard banging without commenting, there's a similar box in the upper right of every page. Put your numbers in there and click the button. You'll be taken right where you are, but you'll know what π is.
Sending messages can be fun! All you have to do is make a game of it. What kind of game, you ask? Well, for example, we could see how many we can send in four seconds, then try to beat that record. (Apologies to Bart and Principal Skinner.)
Objective-C is a dynamic language. When you send a message to an object, gcc emits a call to objc_msgSend() or one of its specialized, similiar functions. Since every Objective-C message send is funneled through objc_msgSend(), making objc_msgSend() as fast as possible is a priority. Let's see how fast we are and if we could do better.
Profiling objc_msgSend()
I wrote some code to see how many times Objective-C could call a method in four seconds. I set an alarm using the alarm() function. Then I sent an increment message to an object in a loop until I received the SIGALRM signal, at which point I output how many times the method ran and exit. I compiled it with gcc4 on Tiger using -O3. Here is my Objective-C code.
Over an average of three runs, I benchmarked 25681135 messages a second. All right.
As Skinner said, let's try to beat that record! And we'll start by profiling. My favorite profiling tool on OS X is, of course, Shark. Let's run it on our executable. Ok, there we go. Shark shows that 16% of the time is spent in the increment method itself, 34% of the time is spent in dyld_sub_objc_msgSend(), and 48% is spent in objc_msgSend() itself. What is this dyld_sub_objc_msgSend() function and why does it take so much time?
You may already know. objc_msgSend() is dynamically linked from a dynamic library, namely, libobjc. In order to call the actual objc_msgSend(), the code jumps to a stub function, dyld_stub_objc_msgSend(), which is responsible for loading the actual objc_msgSend() method and jumping to it. As you can see, the stub function is relatively expensive. If we could eliminate the need for it, we could see a performance improvement of up to 33%.
Plan of attack
Here's one way to get rid of it. Instead of jumping through the stub function, let's grab a pointer to objc_msgSend() itself and always call objc_msgSend() through that pointer. In fact, it's not so different from inlining the stub.
Easier said than done! How will we do this? Well, we could edit the assembly of this little benchmark by hand, or even screw around with the C code, but that's pretty contrived. It would be great if we could make gcc do this work for us.
Yep, we're gonna hack on gcc. Feel free to download it and do it with me! Or just follow along vicariously. For every source file I mention, I will give the path to it in what you just downloaded, and also a link to it on Apple's opensource site.
Getting the source
Download and extract Apple's latest public version of gcc. As of this writing, it's gcc-4061. Put it on a volume with enough space. Fully built, gcc will take up almost 1.1 GB.
Building the source
All extracted? Great. Open up README.Apple in the gcc-4061 directory. It tells you to run two commands:
Guess what? You run the commands. (Notice those are backticks, not single quotes!) Then go get some coffee or something. This may take a while, but we only have to do this once.
Back? Is it done? STILL? Ok, I'll wait.
Testing our build
Done now? Great. Try it out. Compile something, like my Objective-C code, with build/dst/usr/bin/gcc-4.0. Pretty easy:
gcc-4061/build/dst/usr/bin/gcc-4.0 -O3 -framework Foundation test1.m ; ./a.out
26129493
Great! It works! Now let's see if we can add our optimization.
Hacking on gcc
All right. So the plan is to grab a pointer to objc_msgSend, stash it in a function pointer variable, and replace calls to the dynamically linked function objc_msgSend() with jumps through the function pointer. We could do it all in the compiler and not have to change a line of our benchmark code, but for now let's just do the last part - replacing calls to objc_msgSend(). We'll set up the variable in our Objective-C code, where it will be easier to tweak.
Man, this gcc thing is one big scary project. How does it all work? It looks like the source code proper is in the gcc-4061/gcc directory. Let's see if we can figure out what gcc does when we send an Objective-C message to an object. We'll start at the beginning, where gcc starts, and trace its control flow down into its depths. What's the beginning? Well, the lexer/parser seems like a reasonable choice. Grep for YACC...bunch of changelogs...ah-ha! /gcc-4061/gcc/c-parse.in!
Ok, we're in. Looks like a pretty standard-issue grammar. This "objcmessageexpr" thing looks promising. Search for it - it leads us to objc_build_message_expr(). grep for that...it's in /gcc-4061/gcc/objc/objc-act.c. Hey, check it out - at the top, it says that it implements classes and message passing for Objective-C. We're in the right place.
objc_build_message_expr() calls objc_finish_message_expr() calls build_objc_method_call() calls build_function_call()...wait, back up. That last function call looks like it's actually jumping to the objc_msgSend() function. Look for this:
return build_function_call (t, method_params);
Yeah! So t there is the function, either objc_msgSend() or a similar function, and method_params are all the arguments. We want to replace t with our own thing - but only if it's not returning a struct and is not calling super (we'll leave those optimizations for another day).
What should we call our messenger function pointer? Let's call it messengerFunctionPointer! That'll do. You can call yours whatever you like, as long as you keep track of it and make the obvious changes.
So make this change. The new code is in red.
/* ??? Selector is not at this point something we can use inside
the compiler itself. Set it to garbage for the nonce. */
t = build (OBJ_TYPE_REF, sender_cast, method, lookup_object, size_zero_node);
if (sender == umsg_decl) t = lookup_name(get_identifier("messengerFunctionPointer"));
return build_function_call (t, method_params);
Ok, what the heck does that do? Well, it says that if we're doing an ordinary message send (no struct return, no use of super), to call through whatever is in the variable messengerFunctionPointer instead of the function. Note that the code doesn't actually make the messengerFunctionPointer variable for us; that's our privilege, in our C code.
What's interesting about this is that we've hooked into gcc's ordinary variable lookup. Our messengerFunctionPointer variable can be local, global, static, extern, whatever, as long as it is somehow visible in the scope of any code that send an Objective-C message.
We can rebuild it. We have the technology...
That's it! That wasn't so bad. So save the file and rebuild gcc, like you built it before. Since it only has one file to recompile, it won't take long. Here, so you don't have to scroll up:
All done? Ok, let's try recompiling our code from before.
gcc-4061/build/dst/usr/bin/gcc-4.0 -O3 -framework Foundation test1.m
test1.m: In function 'main':
test1.m:29: internal compiler error: Bus error
Uh-oh! An ICE! But of course, it's looking for our variable called messengerFunctionPointer, which doesn't exist (and we don't get any warnings since gcc is looking for the variable after it would normally catch undeclared variables.) So let's add it to my Objective-C code, and point it at objc_msgSend(), which we have to declare as well.
gcc-4061/build/dst/usr/bin/gcc-4.0 -O3 -framework Foundation test1.m; ./a.out
35099819
It worked! And it's faster! I averaged 34967726 messages a second, a 36% gain - even better than the prediction of 34%. And a session with Shark shows that dyld_stub_objc_msgSend() is no longer being called at all.
More, more, more!
Can we do even better? Since it has to load the value of the global variable every time you send a message, maybe if we made it const we could see an even bigger benefit?
id objc_msgSend(id, SEL, ...);
id (* const messengerFunctionPointer)(id, SEL, ...) = objc_msgSend;
gcc-4061/build/dst/usr/bin/gcc-4.0 -O3 -framework Foundation test1.m; ./a.out
26488189
Wha? Making our variable const made our code SLOWER! What's going on? A quick check of the assembly shows that gcc is performing constant propagation on our const variable, replacing calls through the function pointer to calls to dyld_stub_objc_msgSend() again. It's undoing all of our hard work! (And proving that gcc's well meaning optimizations can, in fact, make things slower.) A simple fix:
id objc_msgSend(id, SEL, ...);
id (* const volatile messengerFunctionPointer)(id, SEL, ...) = objc_msgSend;
(Holy type qualifier, Batman! Not only did we find a use for volatile, it actually made things faster!)
Is this good for anything else? For one thing, it allows us to very quickly and dynamically switch among various messenger functions, including our own, so that we can do tricks such as additional logging or fancy message forwarding. We could even do something crazy like add multiple dispatch. And programs built with this technique should (in principle) be backwards compatible enough to run on previous versions of OS X. Unfortunately, this trick does not affect already-compiled libraries, like AppKit.
A closer-to-real-life test
For a more realistic example, here's a simple program that sorts three million objects. The optimization (made a little trickier) improves the run time from 17.93 seconds to 15.7 seconds.
Incidentally, the first person to post in the comments the correct explanation for why I didn't use qsort() in the above code wins my click-pen. Use your real e-mail address for this incredibly cheap swag.
Disadvantages
Any reasons to not use this trick? Yes, lots. For one thing, my gcc change is a kludge. It generates some spurious warnings and may be incorrect in some cases. If anyone decided to implement this optimization seriously, it would have to be much more robust. For another, global variables with position independent code isn't pretty, and absent a way to get fast access to the variable (such as -mdynamic-no-pic, or making it a local variable, or ensuring it's cached in a register) the optimization will have less impact.
Conclusion
So to sum up, objc_msgSend() spends a third of its time in its stub function. By tweaking the compiler to always call objc_msgSend() through a function pointer variable, we can eliminate that overhead and open up some interesting possibilities for dynamically modifying message dispatch.
Compiled BitmapsJune 22nd, 2005
Ancient programmers speak in hushed tones of the legend known as the "compiled bitmap." Ok, no they don't, but there is such a thing. It's a technique that was sometimes used in the DOS days for rapidly drawing an image to the screen. But how can you compile a bitmap? And is there any value remaining in this technique, or should it be left in the dustbin along side TSRs and DOSSHELL? Let's find out!
Blitting
Drawing an image is called "blitting." The usual way we blit is to load a pixel from the source image buffer, store it in the destination, and repeat until we've blitted every pixel.
But with compiled bitmaps, the data for the image is in the instruction stream itself. So instead of "load a pixel from the source," we say "load red," and then store it as usual. Then "load green", or whatever the next color is, and store that, etc. A compiled bitmap is a function that knows how to draw a specific image.
Instruction counts
So an advantage of a compiled bitmap is that there's no need to load data from an image when we blit; the image data is in the instruction stream itself. But this is ameliorated by the fact that we'll have many more instructions in the function. How many more? That depends on the processor architecture, of course, but since I'm a Mac guy, I'll stick to PowerPC.
To load a single 32 bit pixel into a register requires two instructions: one to load each 16-bit half. And storing a pixel requires another instruction. By taking advantage of the literal offset field in the stw instruction, we can avoid having to increment our destination pointer (except when we overflow the 16 bit field every sixteen thousand pixels). The PowerPC also has a special instruction form, the store word with update instructions, stwu, that lets us increment the target pointer for free. But my tests showed that to be slower than stw, which makes sense, since it introduces more inter-instruction dependencies.
But of course, if the next pixel is the same color as the current one, there's no need to load a new color into the register: you can just store the current value again. So sometimes we can get away with only one instruction per pixel. So the number of instructions per pixel in a compiled bitmap ranges between one and three, depending on the complexity of the image and the sophistication of our compiler.
This compares favorably to ordinary blitting, where we have more instructions per pixel (load pixel, store pixel, check for loop exit, and pointer updates). So at first blush, a compiled bitmap may appear ~ 33% faster than ordinary blitting.
Bandwidth
But this isn't the whole story, of course; a processor is only as fast as it can be fed. How much memory bandwidth do we use? In standard blitting, the instruction stream is a very short loop which fits entirely into the instruction cache. The main bandwidth hog is reading and writing the pixels: 32 bits read, 32 bits written. That's 32 bits each way, per pixel.
With a compiled bitmap, the instruction stream no longer fits in the cache, so the instructions themselves become the bandwidth bottleneck. 32 bits for each instruction (remember, there's one to three), and 32 bits to write out each pixel, means between 32 and 96 bits read and 32 bits written per pixel. Based on that, we might expect a compiled bitmap to be up to three times slower than memcpy().
Test approach
I wrote a test program that blits three different images, at three different sizes, using each of three different methods. The images were the standard OS X Stones background image, an image with random pixels generated via random(), and a solid blue image. I blit (blitted?) to the screen using the CGDirectDisplay API, and repeated the tests to an in-memory buffer. The blitters were a memcpy() driven blitter, a bitmap compiler, and (for the screen only) the draw method of an NSBitmapImageRep. In each case, I blit 50,000 times and timed the number of seconds it took. Division gives the frames per second, and multiplying by the number of pixels gives pixels per second.
Here is the Xcode project I wrote. I place it in the public domain. (Note that it outputs frames per second, not pixels per second. You can calculate pixels per second by multiplying the framerate by the number of pixels in a frame. Note that I lowered the test count to 500 from 50,000 so you don't tie up your computer for too long by accident. I also left in the stwu version of the compiler in case you're interested.)
Results
Here's what I got.
Pixels/second for blitting to memory:
Image Size
128x128
256x256
512x512
memcpy
Stones
2,582,493,355
401,030,682
244,721,918
Compiled Bitmap
Stones
961,846,601
116,857,588
116,034,503
memcpy
Random
2,599,446,090
392,847,697
244,445,199
Compiled Bitmap
Random
732896429
116,561,007
115,185,567
memcpy
Solid
2,592,274,147
431,870,370
245,302,313
Compiled Bitmap
Solid
990,974,688
351,106,794
234,451,230
Pixels/second for blitting to the screen:
Image Size
128x128
256x256
512x512
memcpy
Stones
40,984,006
40,984,335
40,933,309
CoreGraphics
Stones
20,115,402
10,588,428
10,611,671
Compiled Bitmap
Stones
13,321,951
13,300,135
13,303,299
memcpy
Random
40,996,351
40,994,852
40,935,011
CoreGraphics
Random
20,128,212
10,581,521
10,602,114
Compiled Bitmap
Random
13,326,014
13,299,336
13,300,511
memcpy
Solid
40,993,883
40,998,191
40,936,245
CoreGraphics
Solid
20,125,009
10,574,159
10,602,177
Compiled Bitmap
Solid
13,324,779
13,321,780
13,310,426
Man, that's boring. All right, let's draw some graphs.
Count the digits...one...two...ok, yeah, note that the scales are very different here. We can blit two and a half billion pixels to memory in the same amount of time as it takes to blit forty million pixels to the screen.
So it's pretty obvious that memcpy() is faster than my bitmap compiler. The only point where my compiled bitmap is competitive is blitting a large solid color.
Ex Post Facto Explanation
Was my Latin right? Darn if I know. Anyways, I noticed that memcpy() is using a sequence of unrolled lvx and stvx instructions. That means Altivec acceleration! It may be part of the reason memcpy() is so fast. Unfortunately, the only way to fill a vector register with literal values is to assemble them in memory and then load them in, so it would not be easy to vectorize the bitmap compiler, except in special cases. The results might be somewaht different on an Altivec-lacking G3.
Blitting the solid image to memory via a compiled bitmap is between two and three times faster than the non-solid images, and is competitive with memcpy(), except in the 128x128 case. I don't know why memcpy() is so much faster in the 128x128 case. I also don't know why blitting to the screen is so much faster with memcpy() compared with the other techniques. If you know or have ideas, please comment on them!
It's also very likely that I've missed a major optimization opportunity. I'm far from a guru when it comes to the PowerPC. If you spot one, please post it in the comments!
Looking ahead
My clumsy tests seem to confirm that compiled bitmaps aren't very fast. But note that the PowerPC has fairly big instructions, so it may not be the best candidate for a bitmap compiler. It takes twelve bytes of PowerPC instructions to write a 32 bit literal to a location in memory, but only six bytes of x86 instructions, which halves our bandwidth requirements. When the ICBMs ship, I'll write a bitmap compiler for them and repeat these tests.
I'm sure you've seen it too, 'cause it was on Slashdot and if you're fishing here, you're definitely an online junkie. I'm talking about that Anandtech article, of course. The one that tries to compare OS X to Linux and a PowerPC to an x86. Lemme see...this one. No more mysteries, they promise!
None of it's pleasant, but what's the worst part? The mySQL results. I know it's painful - you don't have to look again. All right. So why was the G5, at best, 2/3 the speed of any of the other machines?
I don't have an official or authoritative answer. But I think this might have a lot to do with it.
When you commit a transaction to a database, you want to be sure that the data is fully written. If your machine loses power half a second after the transaction completes, you want to know that the data made it to disk. To enable this, Mac OS X provides the F_FULLFSYNC command, which you call with fcntl(). This forces the OS to write all the pending data to the disk drive, and then forces the disk drive to write all the data in its write cache to the platters. Or that is, it tries to - some ATA and Firewire drives lie and don't actually flush the cache. (The check's in the mail, really...)
F_FULLFSYNC is pretty slow. But if OS X didn't do it, you might end up with no data written or partial data written, even out of order writes, if you lose power suddenly.
Well! mySQL performs a F_FULLFSYNC on OS X, and not on Linux; as far as I know Linux doesn't provide a way to do this.
It's true that mySQL calls fsync() on both, but fsync() doesn't force the drive to flush its write cache, so it doesn't necessarily write out the data. Check out http://dev.mysql.com/doc/mysql/en/news-4-1-9.html and Dominic's comments at the bottom. Oh, and if you missed it, above, look at this Apple mailing list post.
So OS X takes a performance hit in order to fufill the contract of transactions. Linux is faster, but if you lose your wall juice, your transaction may have not been written, or been partially written, even though it appeared to succeed. And that's my guess as to the main reason OS X benchmarked slower on mySQL.
Again, this isn't an official explanation, and I'm not qualified to give one. But given that Anandtech missed this issue entirely, I'm not sure they are either.
What about Anandtech's theory, here? Could the mySQL benchmark be due to the LMbench results? I must confess, this part left me completely bewildered.
They claim that making a new thread is called "forking". No, it's not. Calling fork() is forking, and fork() makes processes, not threads.
They claim that Mac OS X is slower at making threads by benchmarking fork() and exec(). I don't follow this train of thought at all. Making a new process is substantially different from making a new thread, less so on Linux, but very much so on OS X. And, as you can see from their screenshot, there is one mySQL process with 60 threads; neither fork() nor exec() is being called here.
They claim that OS X does not use kernel threads to implement user threads. But of course it does - see for yourself.
/* Create the Mach thread for this thread */
PTHREAD_MACH_CALL(thread_create(mach_task_self(), &kernel_thread), kern_res);
They claim that OS X has to go through "extra layers" and "several threading wrappers" to create a thread. But anyone can see in that source file that a pthread maps pretty directly to a Mach thread, so I'm clueless as to what "extra layers" they're talking about.
They guess a lot about the important performance factors, but they never actually profile mySQL. Why not?
Whew, I'm a bit wore out. I'll leave you to draw your own conclusions, and I hope you post them in the comments.
NilMay 29th, 2005
What does sending a message to nil do in Objective-C? What value does it return? You probably know that if the method is declared to return an object, you get back nil, but what if the method is declared to return a char? An int? A long long? A float? A struct? And how does it all work?
Let's find out!
objc_msgSend
Here's what I do know. When you send a message to an object, such as [someObject doSomething], the compiler compiles that into a function call to the objc_msgSend() function (or objc_msgSend_stret() if the method is declared to return a struct; more on that below). So what does objc_msgSend() do with nil?
Fortunately, that code is available publicly, from Apple's public source page. We want the objc-msg-ppc.s file (Warning: Apple ID required). .s means assembly, but don't worry, we can handle it.
(I am displaying a few snippets of that code in this post. All such code is Copyright Apple Computer.)
Where's the objc_msgSend() function? Oh, there it is; search for "ENTRY _objc_msgSend".
ENTRY _objc_msgSend
; check whether receiver is nil
cmplwi r3,0 ; receiver nil?
beq- LMsgSendNilSelf ; if so, call handler or return nil
So the first instruction cmplwi r3,0 compares r3 (that's the object) against 0, and the second instruction beq- LMsgSendNilSelf jumps to LMsgSendNilSelf if they were equal.
LMsgSendNilSelf
Ok, so what's this LMsgSendNilSelf thingy? Search for it within the file...ah-ha, there it is. This is where we go if the message receiver is nil, but what does it do?
LMsgSendNilSelf:
mflr r0 ; load new receiver
bcl 20,31,1f ; 31 is cr7[so]
1: mflr r11
addis r11,r11,ha16(__objc_nilReceiver-1b)
lwz r11,lo16(__objc_nilReceiver-1b)(r11)
mtlr r0
cmplwi r11,0 ; return nil if no new receiver
beqlr
mr r3,r11 ; send to new receiver
b LMsgSendReceiverOk
The first six instructions within LMsgSendNilSelf are just there to load the global variable __objc_nilReceiver into register r11 (yeah, six instructions just to load a variable! Globals with position independent code sure isn't pretty). Then it compares that variable against nil, via cmplwi r11, 0, and if it was nil the whole objc_msgSend() function returns. No return value; it just returns.
(If __objc_nilReceiver were not nil, it moves __objc_nilReceiver into r3, where the message receiver goes, and acts like the receiver was __objc_nilReceiver all along, meaning that __objc_nilReceiver is there to let you replace the default message-to-nil behavior with your own! How cool is that!?)
What gets returned
So to sum up, if you send a message to nil, it's as if you executed a C function that just called return without specifying any return value. So what return value does that give us? I guess we need to know how Mac OS X on the PowerPC returns values.
Well, that depends on the type the function is declared to return! That stuff is all documented in the lovely PowerPC Runtime Architecture Guide, which is also hiding out somewhere in /Developer on your system. Ugh, what a mess. Ok, here's what we're after: Function Return. This is what it says, paraphrased:
If a function returns a pointer or an integral type (other than long long), the return value goes in r3, the fourth general purpose register.
If a function returns a floating point value, the return value goes in FPR1, a floating point register.
If a function returns long long, the upper half goes in r3, the lower half in r4.
Struct returning works like this: the caller makes space for the return value and sticks a pointer to the space in r3 (and therefore starts putting parameters in r4 rather than r3), and the callee is responsible for copying its return value into that space. Now we see why struct returns need that special objc_msgSend_stret() function: all the parameters are one register off from where they usually are.
But wait, isn't r3 the same register where we put the object we sent the message to in the first place? Sure is! So when you send a message to nil where the method is declared to return an object, you get back the very same nil for the return value. The function doesn't touch the object parameter, and since the return value is in the same place as the receiver parameter to objc_msgSend(), if the receiver is nil then so is the return value. Lucky!
Types, types, types
And since ints, shorts, chars, and longs are also returned in r3, the same thing happens. Sending a message to nil where you expect to get any of those types back will always give you 0.
What about long long, in which case the return value is half in r3 and the other half in r4? Well, since objc_msgSend() doesn't touch r4 either, what we send is what we get back, and in this case we send the selector in r4. So for the case of a long long, we expect to get the top 32 bits all 0 and the bottom 32 bits equal to the selector we sent. We will never get 0 back if we send a message to nil and expect a long long. Instead, we get the selector converted to a long long!
And floating point? objc_msgSend() doesn't touch the floating point registers, so we'll get back whatever happened to be in FPR1 when we sent the message.
Ok, now for the trickiest case: structs. objc_msgSend_stret() behaves identically to objc_msgSend() with regard to a nil-receiver. And remember that it's the callee's responsibility to copy the return value into the caller provided space. Since objc_msgSend_stret() neglects to do that, the data in the space provided by the caller is unchanged. This often means that code like myPoint = [nil someMethodReturningPoint]; will leave myPoint unchanged (but this behavior is dependent on the compiler's optimizations, and so you shouldn't rely on it).
Phew, my hat's off to you if you trudged through all that. Hopefully you found something new to you.
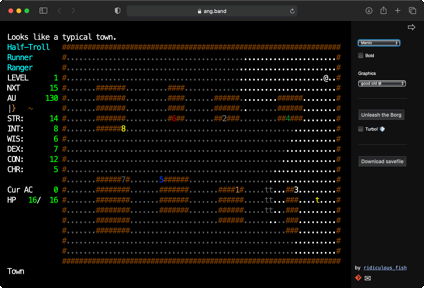
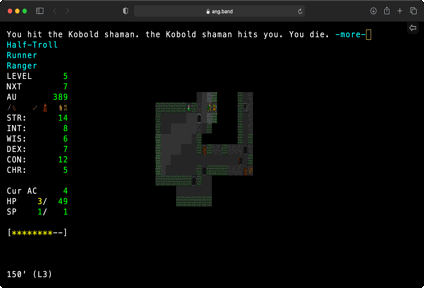
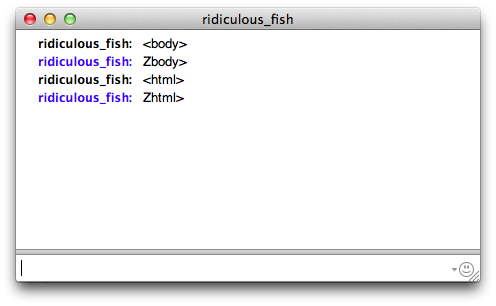


 Guest blogger: Gollum (Smeagol)
Guest blogger: Gollum (Smeagol)

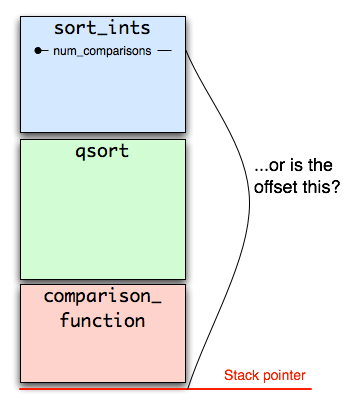
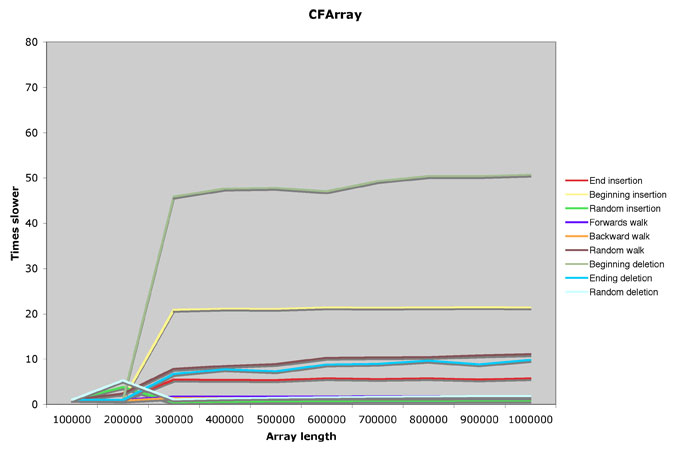
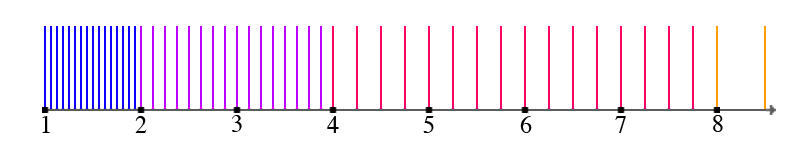

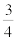 . Yeah.
. Yeah.
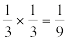 , so the chance of that NOT happening is one minus that, uhm,
, so the chance of that NOT happening is one minus that, uhm, 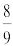 .
.
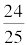 . And so on. Ok, so the probability that A and B are not both divisible by a prime number P is
. And so on. Ok, so the probability that A and B are not both divisible by a prime number P is 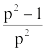 .
.
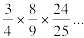
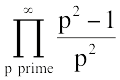
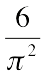 .
.




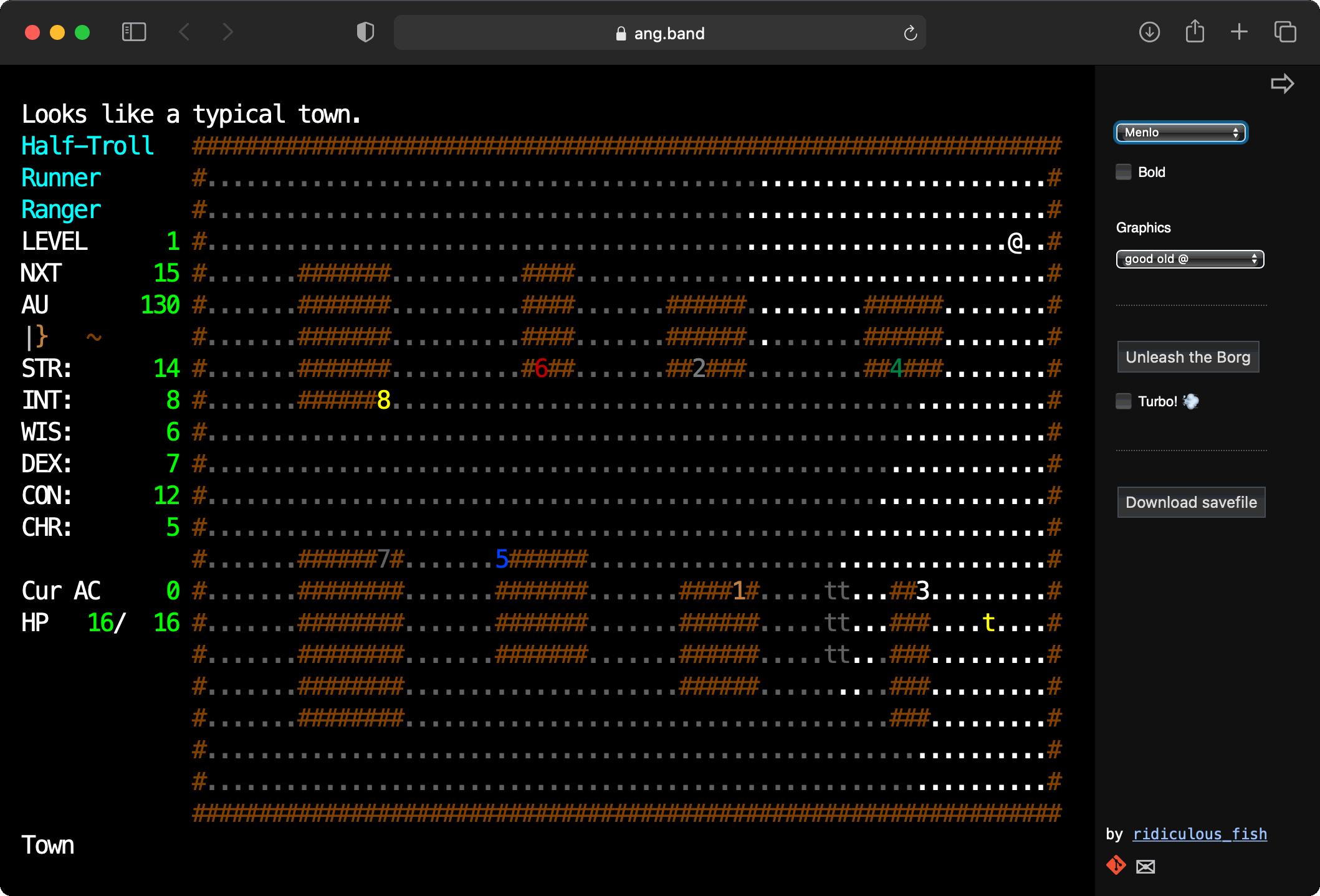
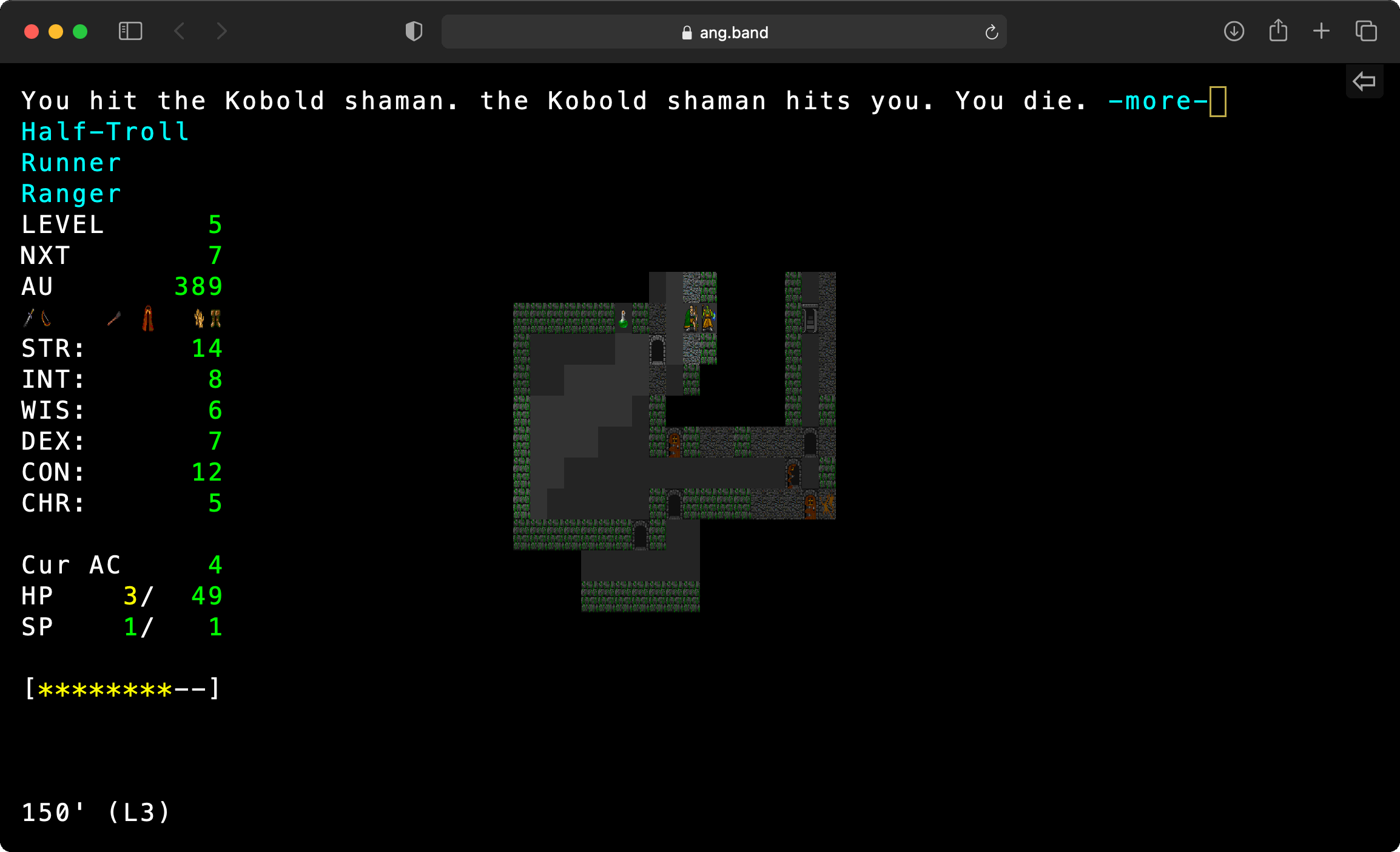
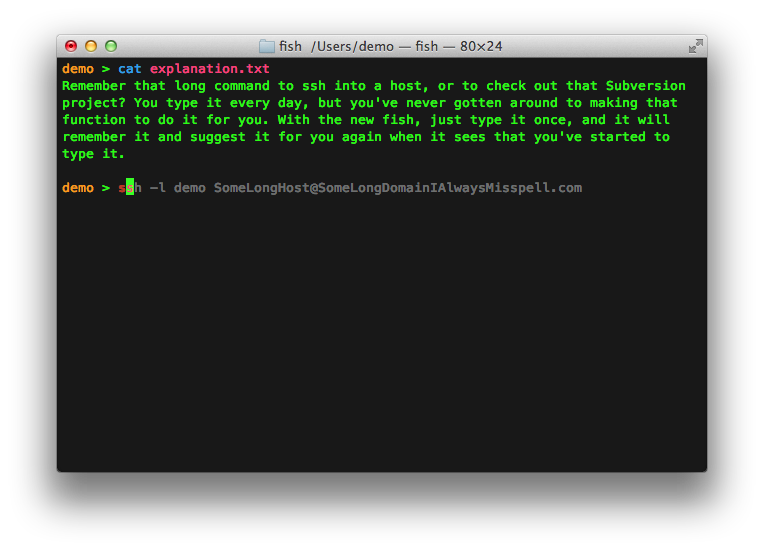{kind=link}
{kind=link}
{kind=link}
{kind=link}
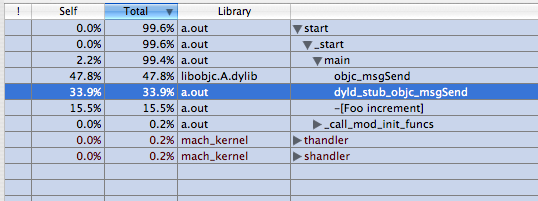{kind=link}
{kind=link}
{kind=link}
{kind=link}